梳理 Segmentation(分割) 相关介绍,数据集,算法
Intro
Foreword
- 相信时至今日,分割作为三大基础任务,是被广为熟知的
- 值得一提的是,分割任务往往被认为有两类
- 语义分割 semantic segmentation
- 语义分割只区分类别不区分个体
- 代表作的有 FCN Deeplab 系列
- 实例分割 instance segmentation
- 实例分割不仅区分类别,对同类别的不同个体也需要区分
- 代表作有 Mask-RCNN
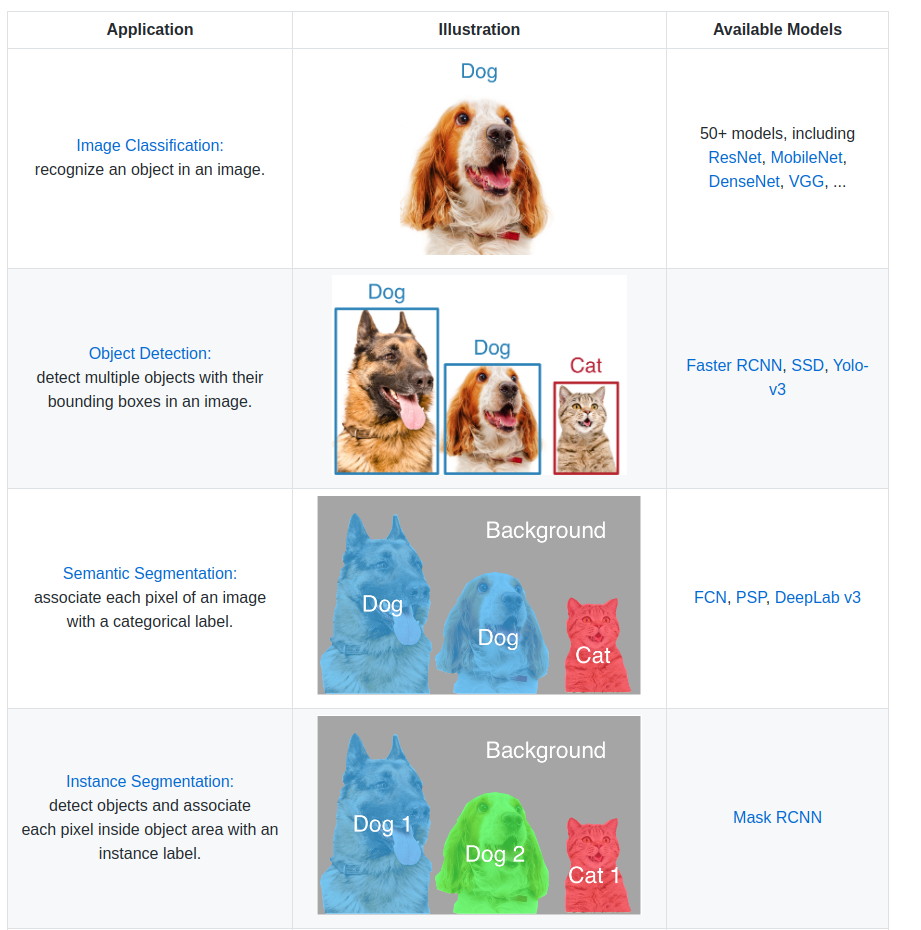
- 语义分割 semantic segmentation
- (借用 gluoncv的一张图来说明)
Algorithm
Semantic Segmentation
Unet
- paper U-Net: Convolutional Networks for Biomedical Image Segmentation
- git https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
- 当然 git 上非官方的也是一抓一大把
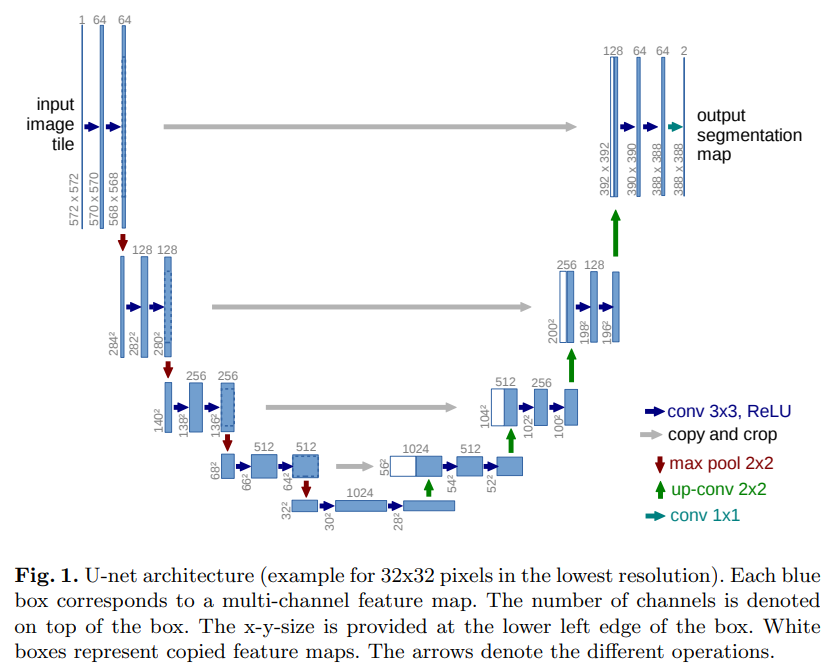
- 非常经典的encode-decode结构,其特点是在decode时高级特征会不断与低级特征融合,对图像本身的结构和语义保护地很好,有效地使局部特征得到充分表现
Segnet
- paper SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation
- code http://mi.eng.cam.ac.uk/projects/segnet/
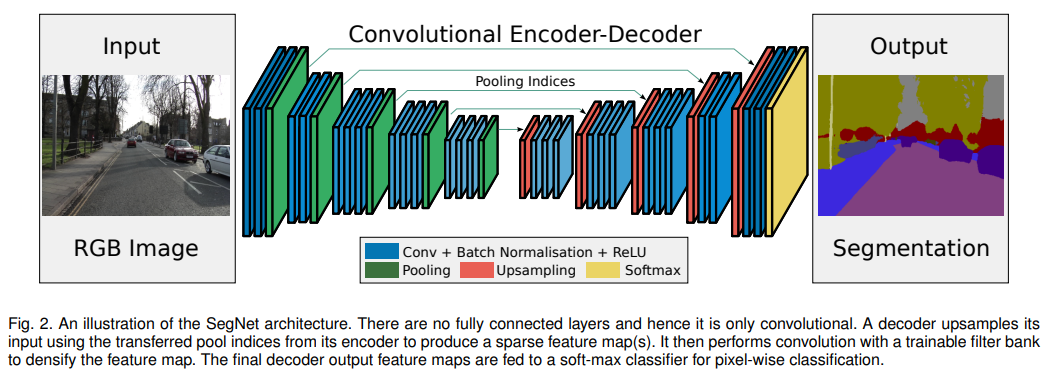
- 和Unet很相似,文章里提到的不同点也是有点牵强。。
- As compared to SegNet, U-Net [16] (proposed for the medical imaging community) does not reuse pooling indices but instead transfers the entire feature map (at the cost of more memory) to the corresponding decoders and concatenates them to upsampled (via deconvolution) decoder feature maps. There is no conv5 and max-pool 5 block in U-Net as in the VGG net architecture. SegNet, on the other hand, uses all of the pre-trained convolutional layer weights from VGG net as pre-trained weights.
Deeplab v1 & v2
- paper DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
- home http://liangchiehchen.com/projects/DeepLab.html
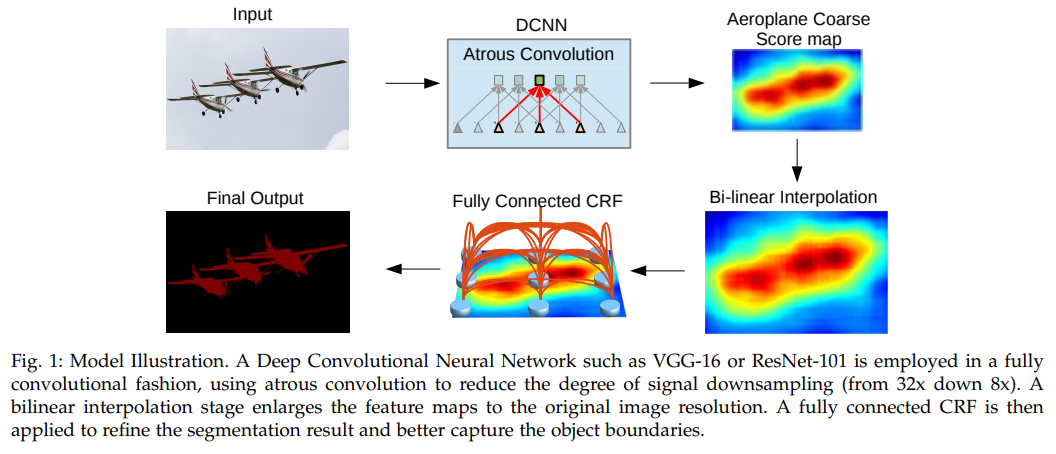
- 在那个年代多阶段还被普遍认为优于end2end,DCNN extract Feature, upsample, FC CRF得到结果。这是deeplab v1的主体思想
- CRFs have been broadly used in semantic segmentation to combine class scores computed by multi-way classifiers with the lowlevel information captured by the local interactions of pixels and edges [23], [24] or superpixels [25]. Even though works of increased sophistication have been proposed to model the hierarchical dependency [26], [27], [28] and/or highorder dependencies of segments [29], [30], [31], [32], [33], we use the fully connected pairwise CRF proposed by [22] for its efficient computation, and ability to capture fine edge details while also catering for long range dependencies.

- 本文最大的贡献之一是带动了Astro conv在seg任务上的发展
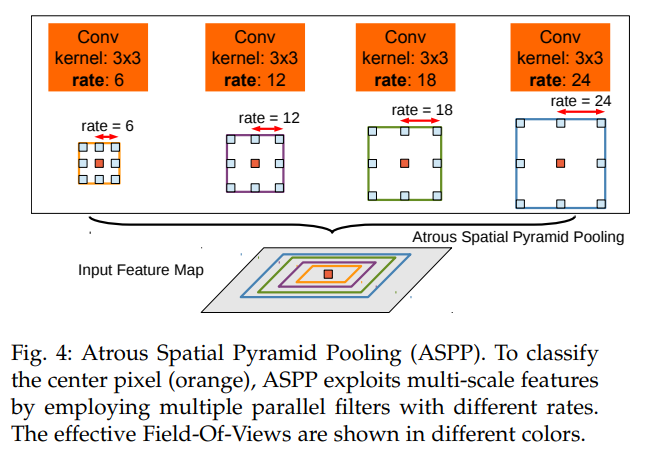
- 有ASPP的版本成为deeplab v2也是同样的出色,多rate的astro conv拼凑而成
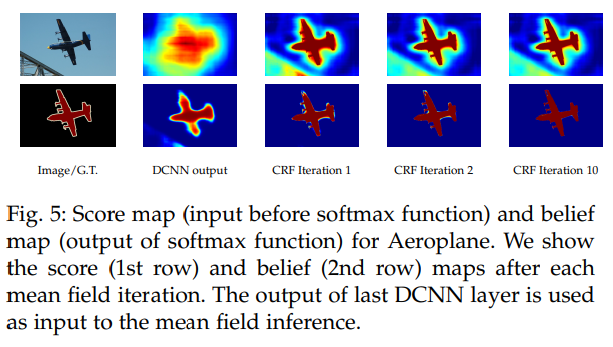
- 通过CRF的持续迭代,边缘信息变得充分,分割结果更加完美
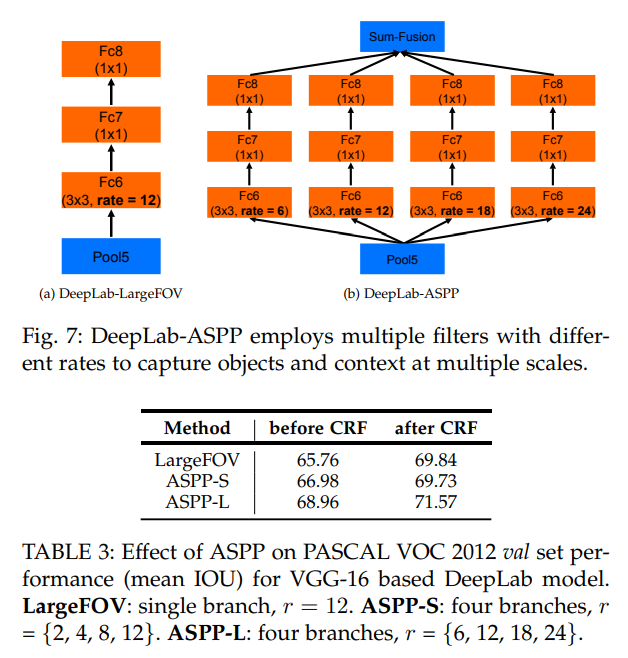
- FOV相当于是单通道的ASPP,实验证明,large rate的aspp效果有显著提高
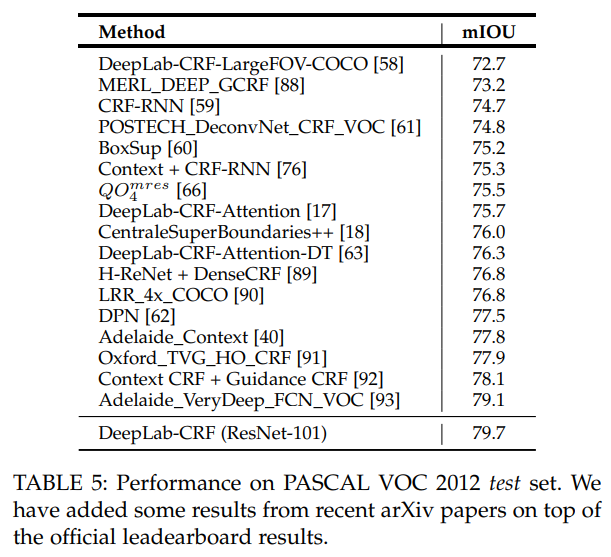
- 说什么也要sota一下
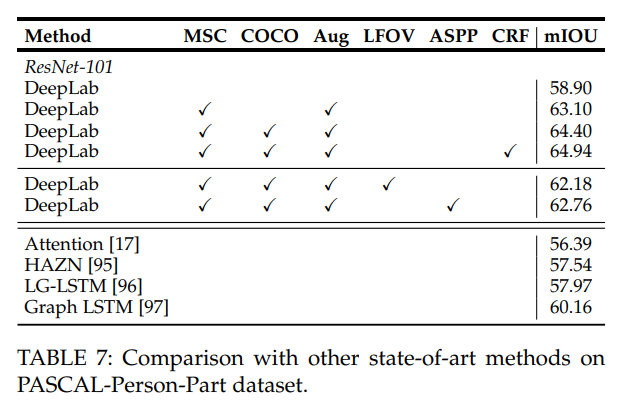
- 有趣的是,ASPP在 PASCAL-Person-Part 上表现不佳,不如不用
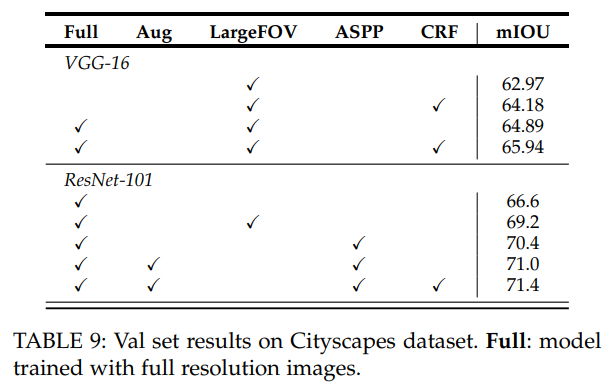
- Cityscapes 上ASPP管用
FCN
- paper Fully Convolutional Networks for Semantic Segmentation
- git https://github.com/shelhamer/fcn.berkeleyvision.org
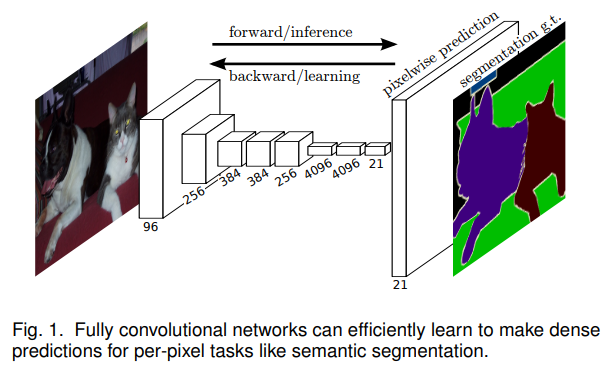
- 非常简洁直接,打开seg新世界大门
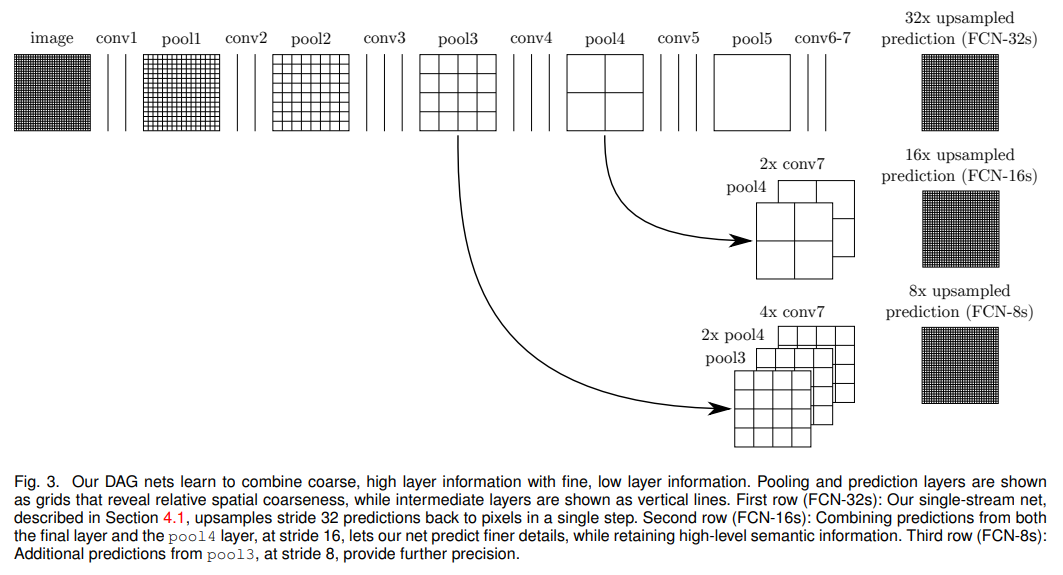
- 同时,FCN也开启了多level特征融合的大门
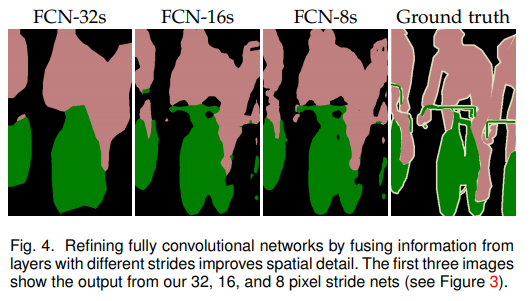
- 32s 16s 8s 表示 downsample 2**(5 4 3) 的结果,肉眼可见的更好了
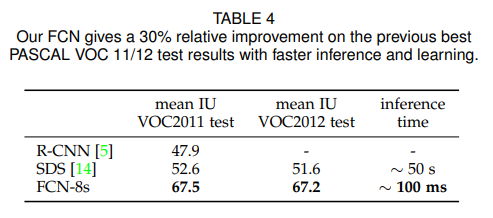
- 结构简洁 结果不错 速度快 还要啥自行车
Enet
- paper ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
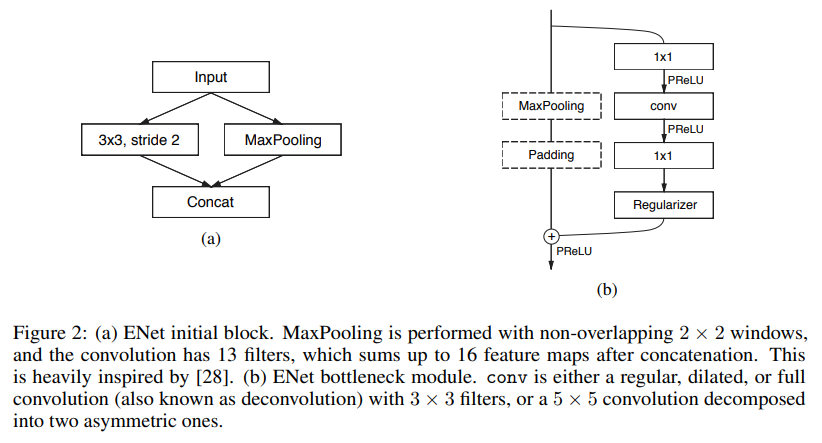
- 开始意识到maxpooling在初级阶段对input的伤害,使用一个3x3 stride2缓解信息丢失;bottleneck 的设计估计是参考了 res,略有一些不同,使用了prelu
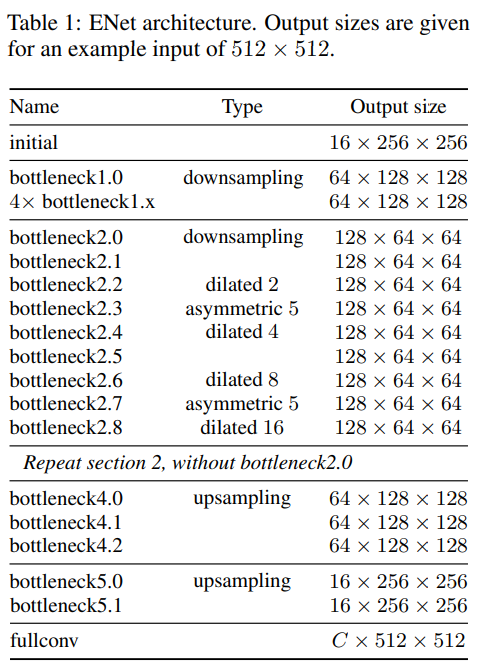
- 主体结构,在stage2 stage3 都有递增的dilated conv
- asymmetric
- Sometimes we replace it with asymmetric convolution i.e. a sequence of 5 × 1 and 1 × 5 convolutions isntead of 5 x 5.
- asymmetric
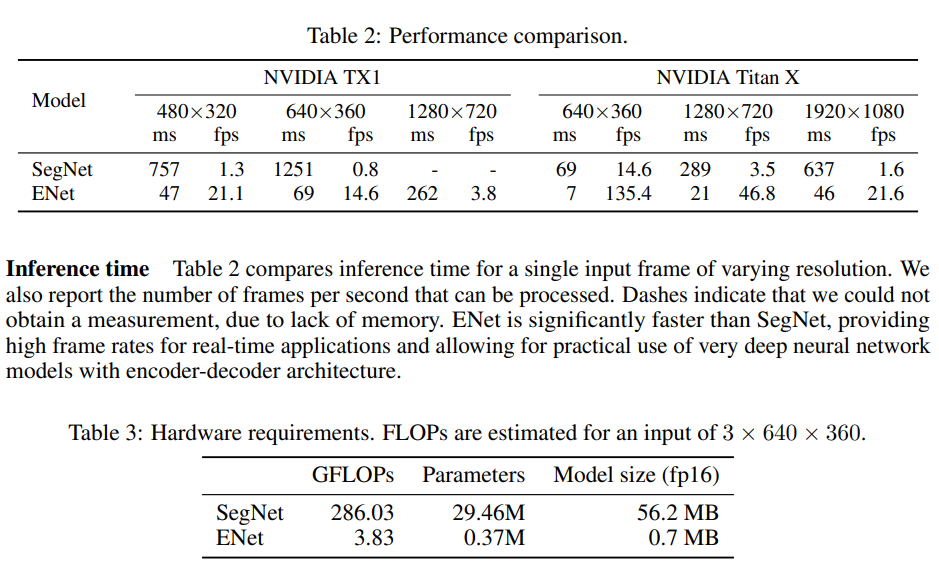
- 展示了相对segnet的速度优势
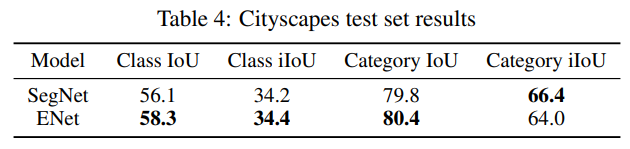
- cityscapes 略逊 segnet
PSP
- paper Pyramid Scene Parsing Network
- semantic seg 扛把子
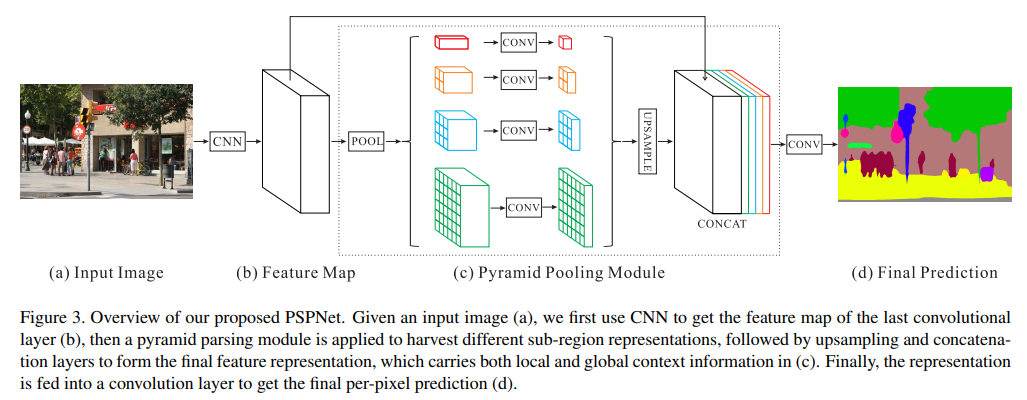
- 直接上代码,非常容易理解
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def _PSP1x1Conv(in_channels, out_channels, norm_layer, norm_kwargs):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
norm_layer(out_channels, **({} if norm_kwargs is None else norm_kwargs)),
nn.ReLU(True)
class _PyramidPooling(nn.Module):
def __init__(self, in_channels, **kwargs):
super(_PyramidPooling, self).__init__()
out_channels = int(in_channels / 4)
self.avgpool1 = nn.AdaptiveAvgPool2d(1)
self.avgpool2 = nn.AdaptiveAvgPool2d(2)
self.avgpool3 = nn.AdaptiveAvgPool2d(3)
self.avgpool4 = nn.AdaptiveAvgPool2d(6)
self.conv1 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
self.conv2 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
self.conv3 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
self.conv4 = _PSP1x1Conv(in_channels, out_channels, **kwargs)
def forward(self, x):
size = x.size()[2:]
feat1 = F.interpolate(self.conv1(self.avgpool1(x)), size, mode='bilinear', align_corners=True)
feat2 = F.interpolate(self.conv2(self.avgpool2(x)), size, mode='bilinear', align_corners=True)
feat3 = F.interpolate(self.conv3(self.avgpool3(x)), size, mode='bilinear', align_corners=True)
feat4 = F.interpolate(self.conv4(self.avgpool4(x)), size, mode='bilinear', align_corners=True)
return torch.cat([x, feat1, feat2, feat3, feat4], dim=1) - 就是avgpooling到不同的尺度获取不同粒度的特征信息
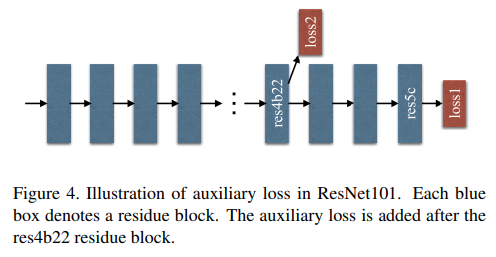
- aux loss 是一个由stage4出来的辅助loss,接的haed是FCN的head(没有psp模块)
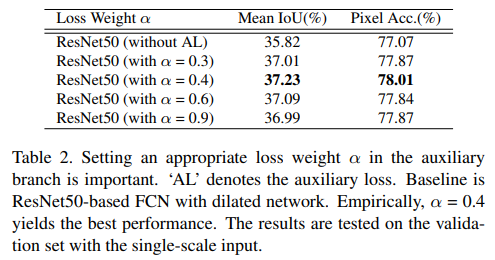
- 作者在Ablation Study中对这个aux loss进行了分析,这玩意就是好使啊怎么都加点
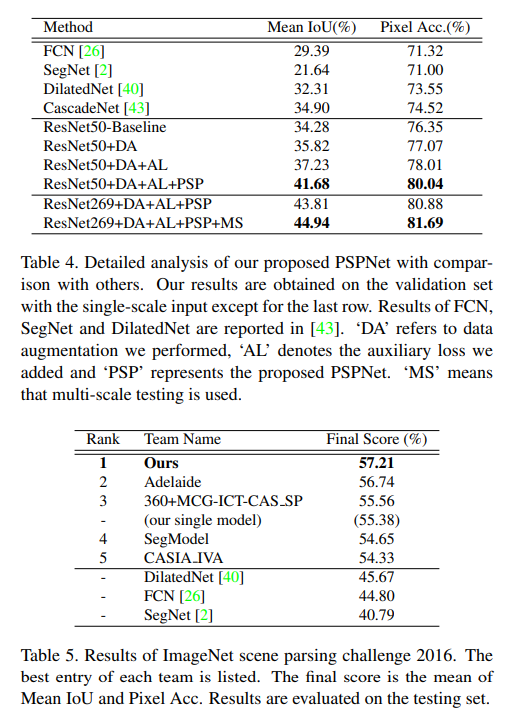
- 展示了PSP的渐进加点方法在ImageNet scene parsing challenge 2016上
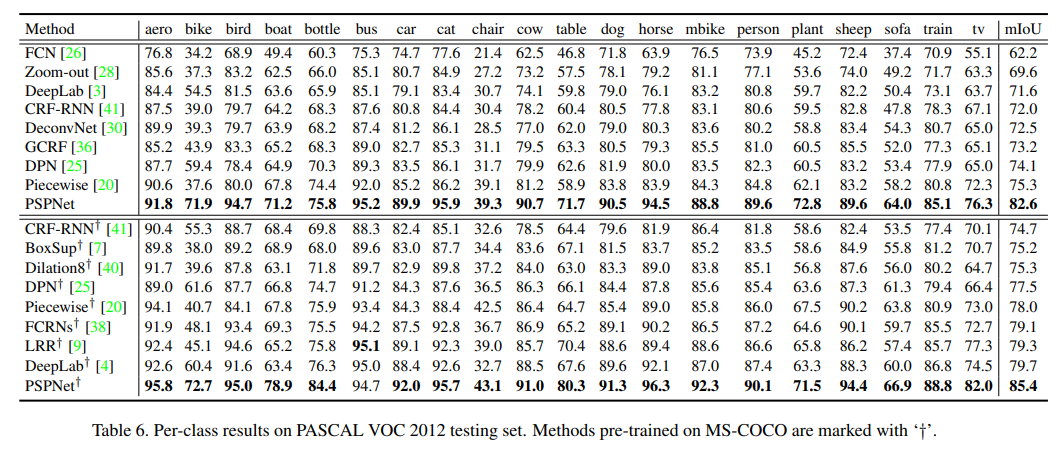
- PSP效果堪称惊艳
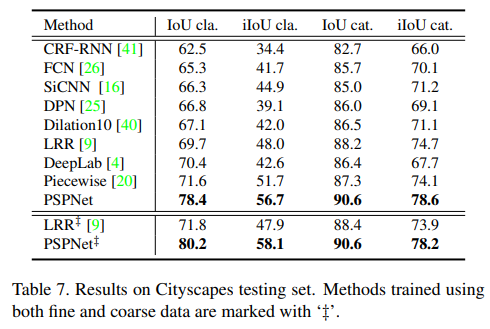
- Cityscapes 当然也不会放过
ICNet
- paper ICNet for Real-Time Semantic Segmentation on High-Resolution Images
- git https://github.com/hszhao/ICNet
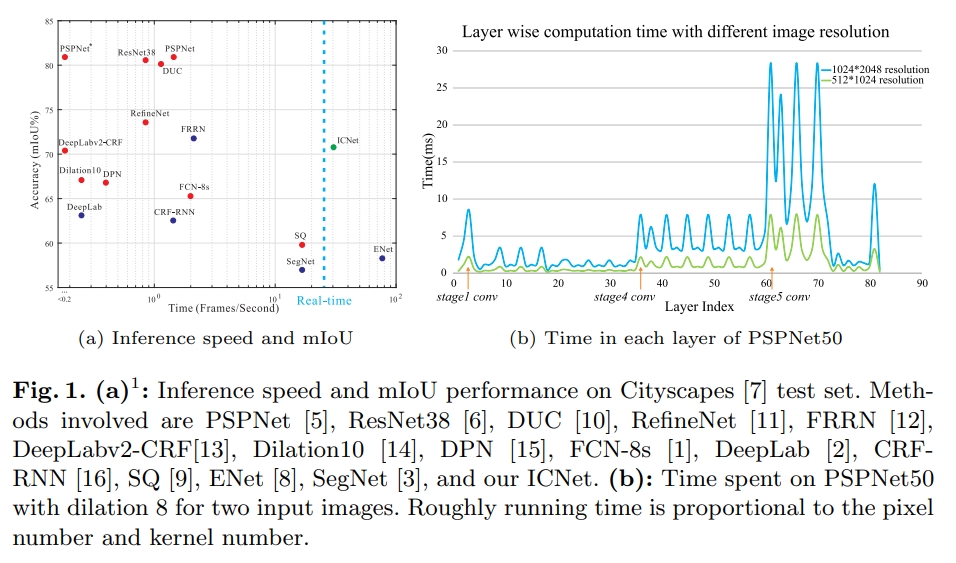
- 虽然PSP很不错,但是不够快,ICNET致力于 acc 和 speed的均衡
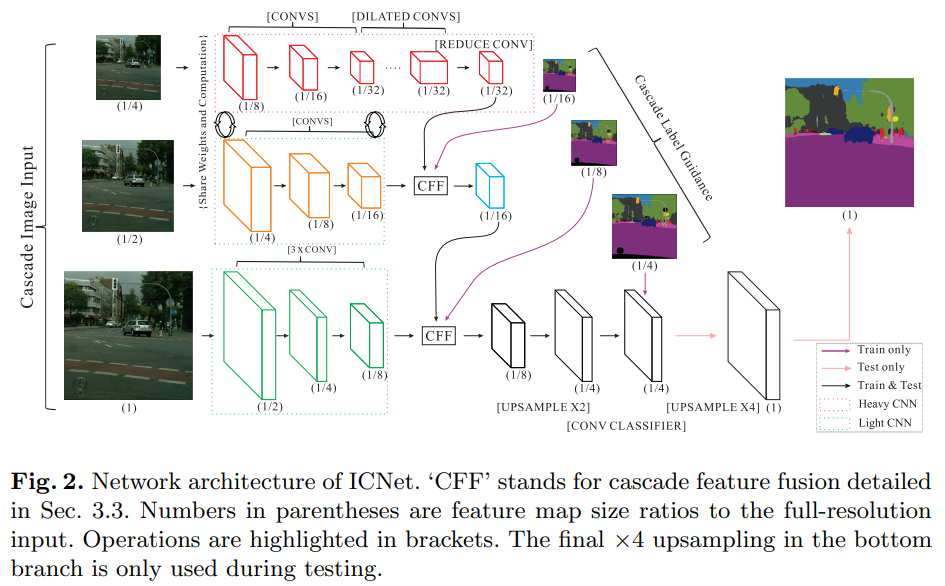
- 通过三个不同大小的input三个不同的子网络的特征进行融合,得到最终结果
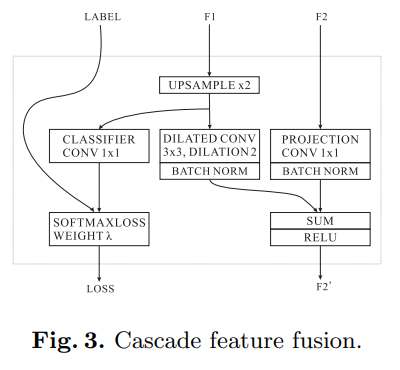
- CFF的细节
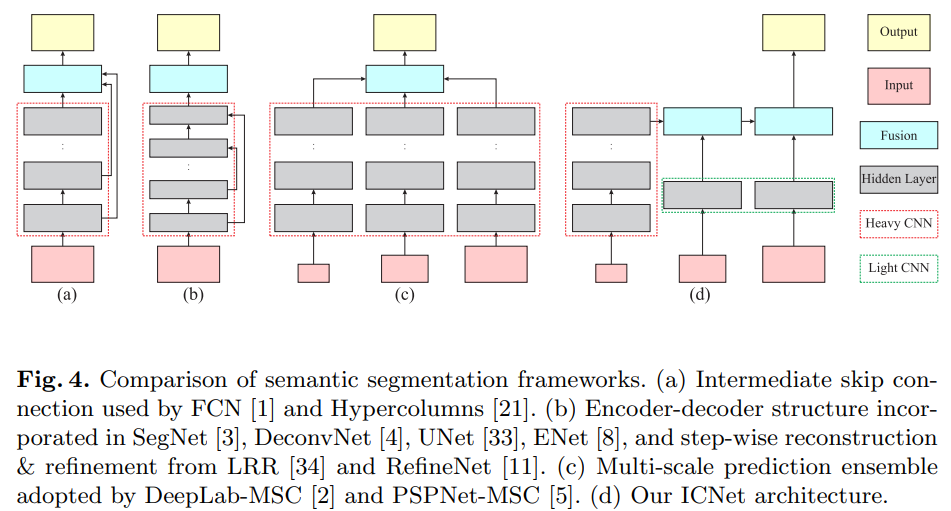
- 列出了几种 semantic segmentation 的常见的structure。我对他说的 ours(d) 是有疑义的,他其实每一个子网络都有output
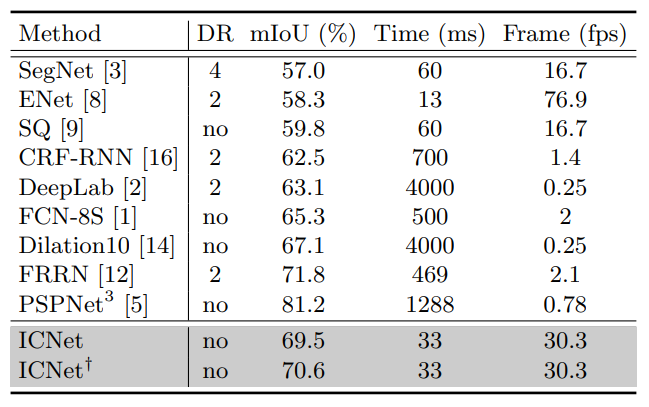
- CityScapes 结果,yolo策略,快的没我好,好的没我快
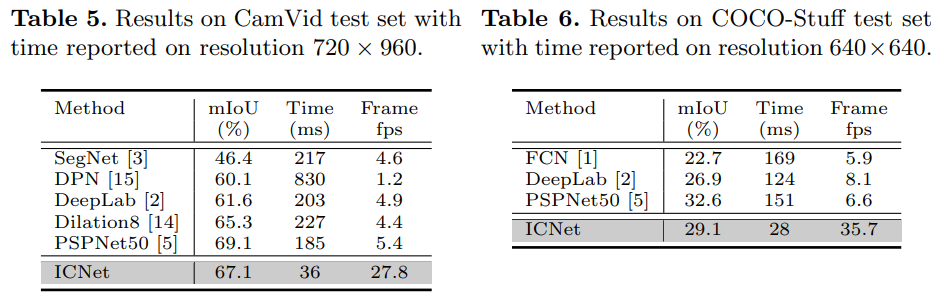
- 在CamVid和CoCoStuff上也是一样的不错
DenseASPP
- paper DenseASPP for Semantic Segmentation in Street Scenes
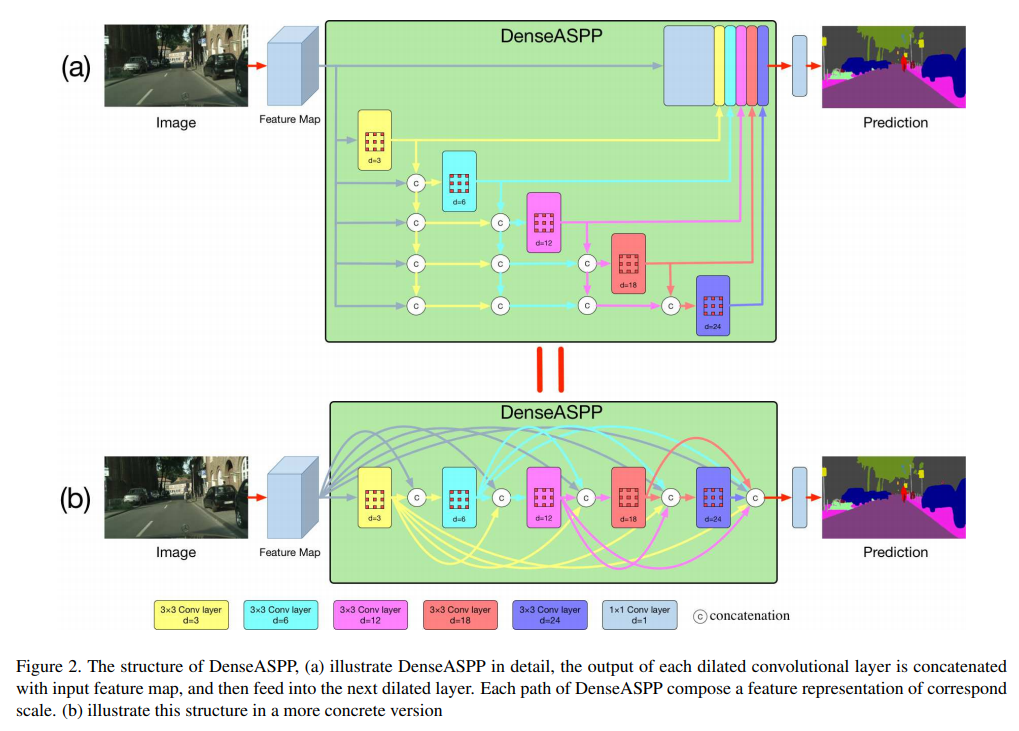
- 受启发于 densenet,给aspp也dense上
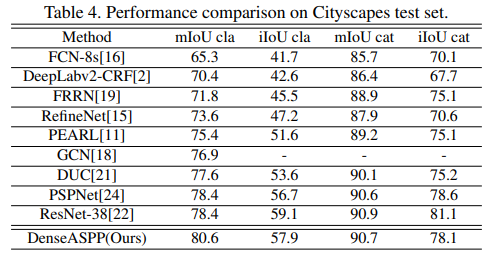
Deeplab v3
- paper Rethinking Atrous Convolution for Semantic Image Segmentation
- 主要就是改进了ASPP
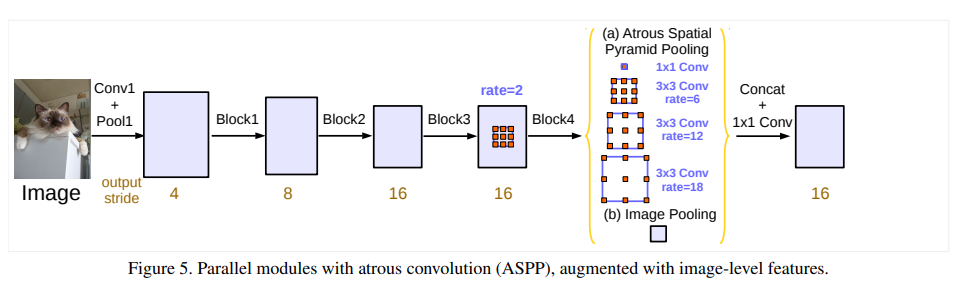
- 在ASPP上加了一个image pooling,并在block4上使用了rate=2的dilate conv
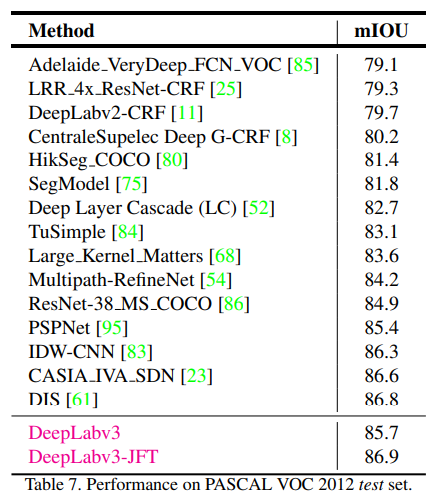
- 相较PSP有少量提升,JFT指pretrained on JFT dataset
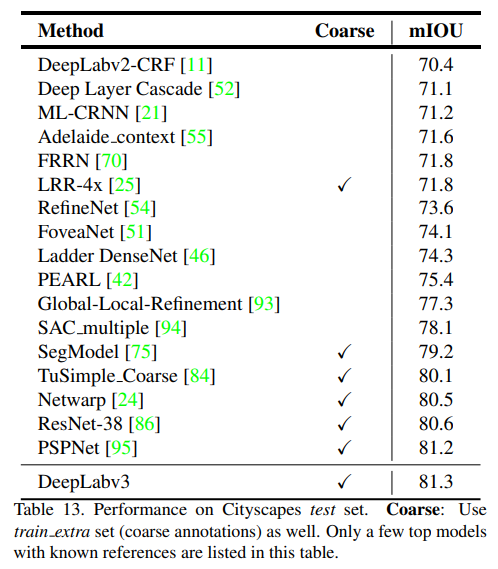
- CityScapes上也是如此
Deeplab v3+
- paper Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
- git https://github.com/tensorflow/models/tree/master/research/deeplab
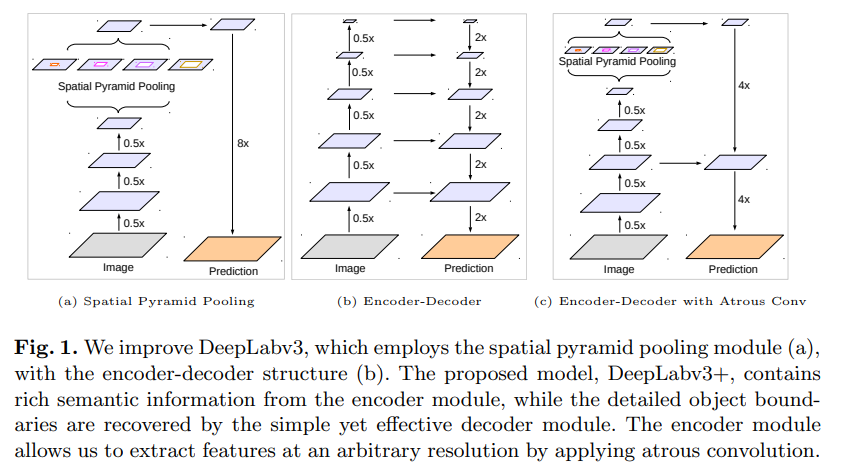
- a是deeplab v3的结构,b是常见的encode-decode结构,相结合成c成为Deeplab v3
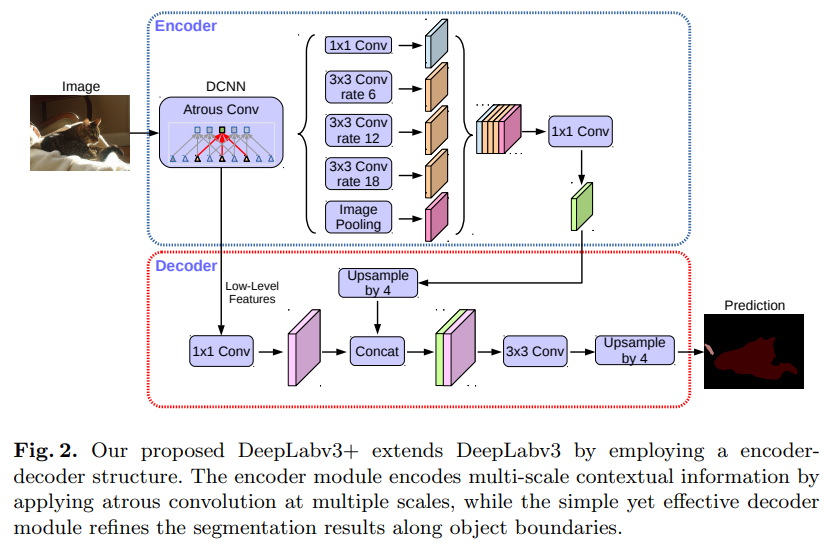
- 结构简单清晰
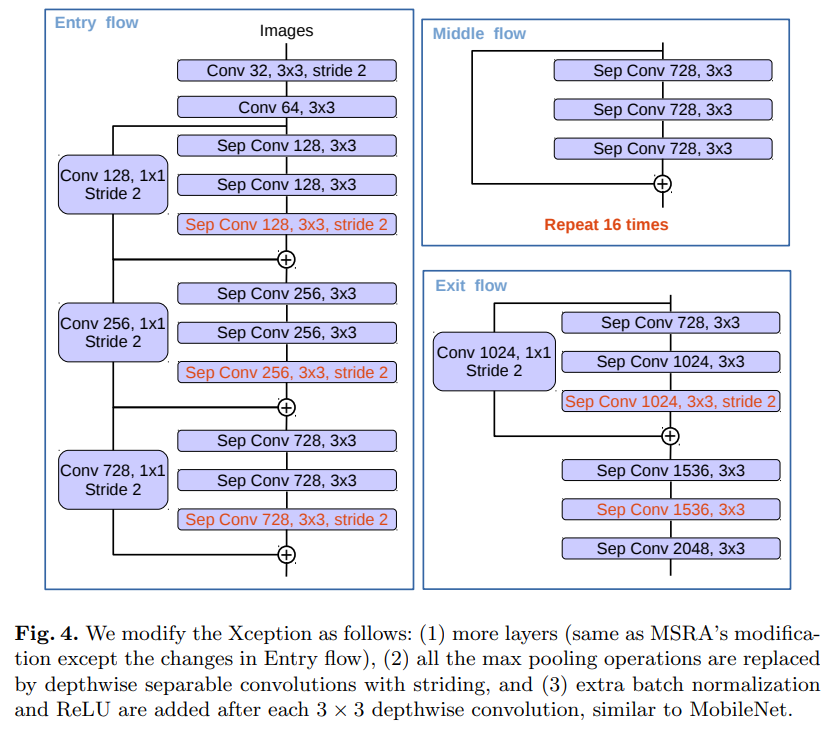
- 顺路玄学设计一把 Xception
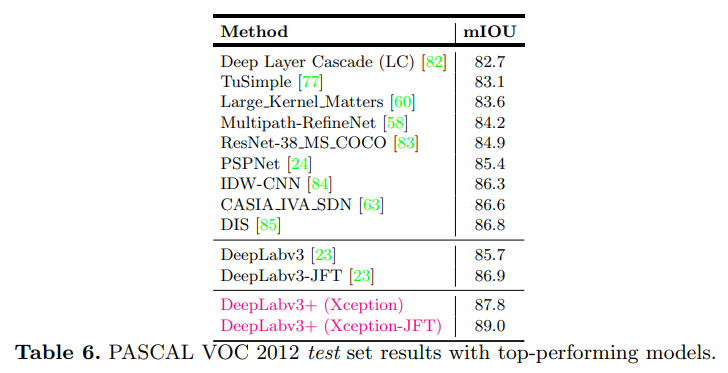
- 得益于backbone和高低阶特征融合,进步很大
EncNet
- paper Context Encoding for Semantic Segmentation
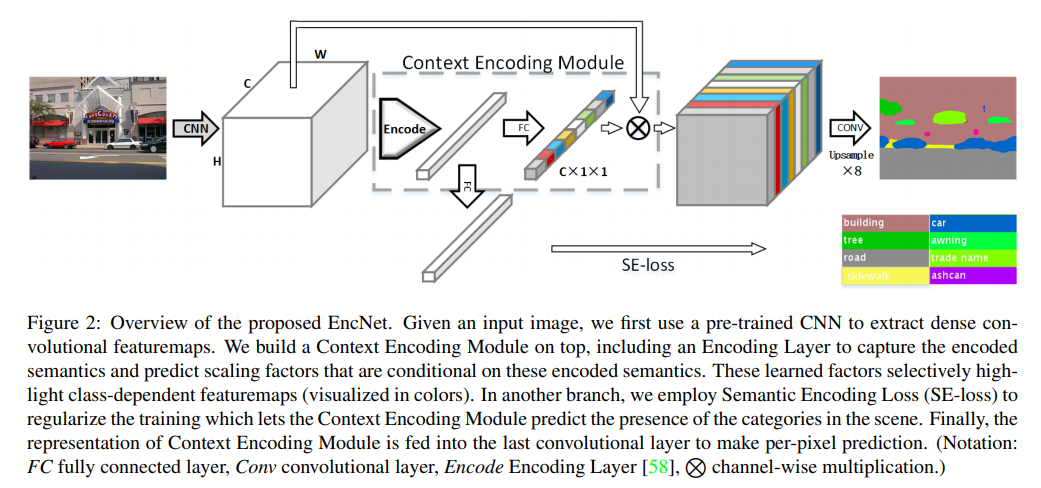
- 对最后的结果重新分配权重,并使用一个新的se loss用来监督监督在这张图中某一个类存在的概率
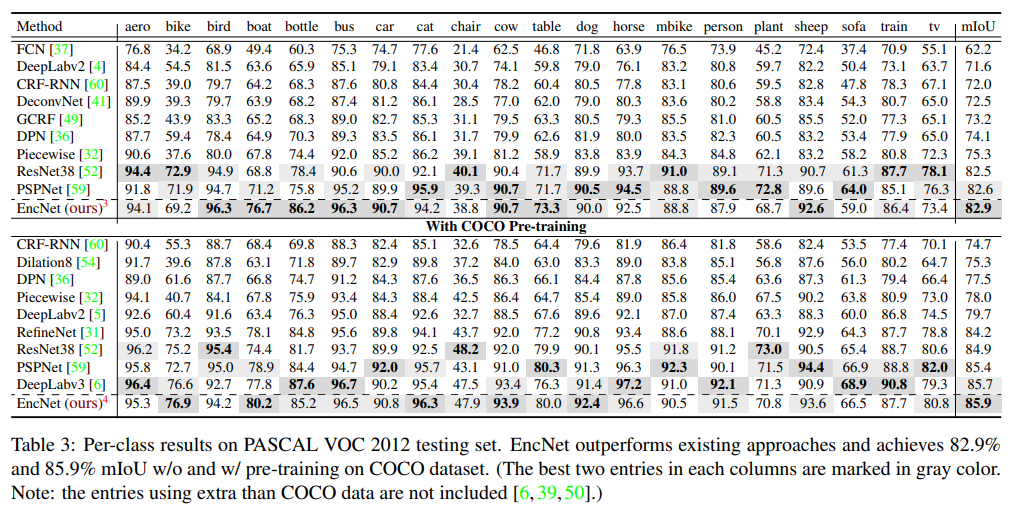
- 相较于早它一个月发布的 deeplab v3+,这个结果实在不够看了
BiSeNet
- paper BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
- Megvii出品
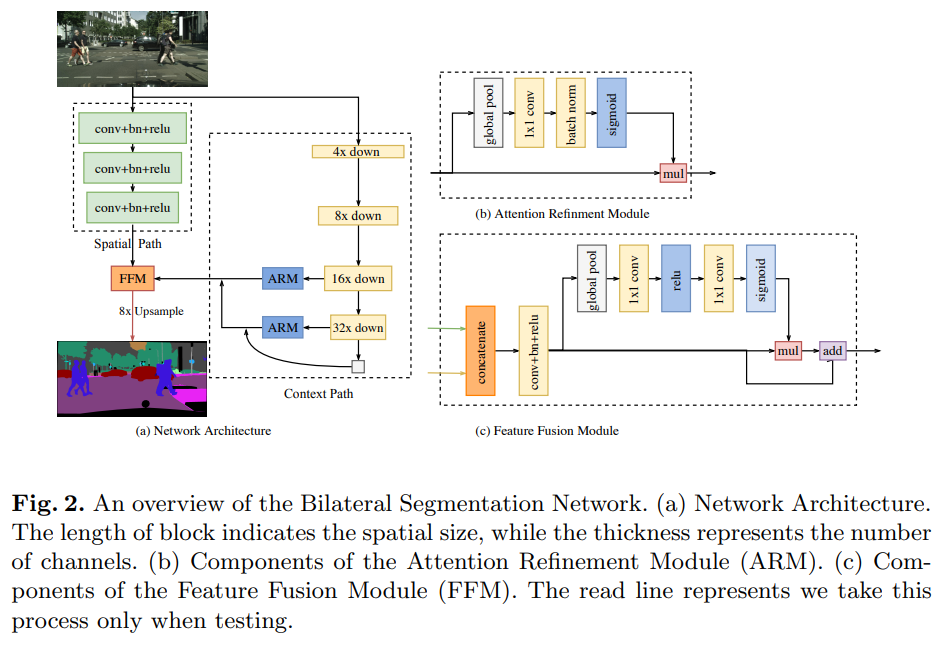
- 这个arm就是去除了缩放channel俩conv的se,ffm是一个经典的attention结构,这里成为是特征融合模块
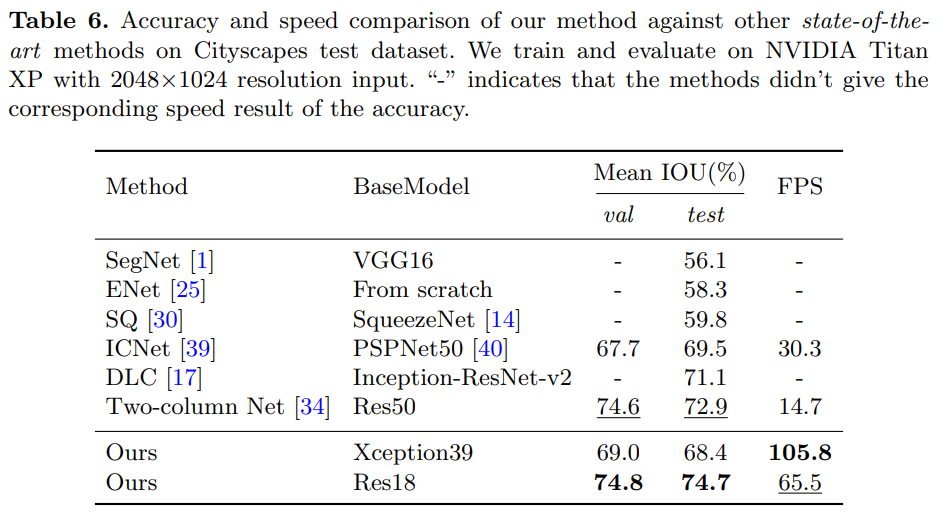
- 对比之前的性价比之王 ICNet,同精度下速度提升3倍;大幅提升精度下速度也翻倍
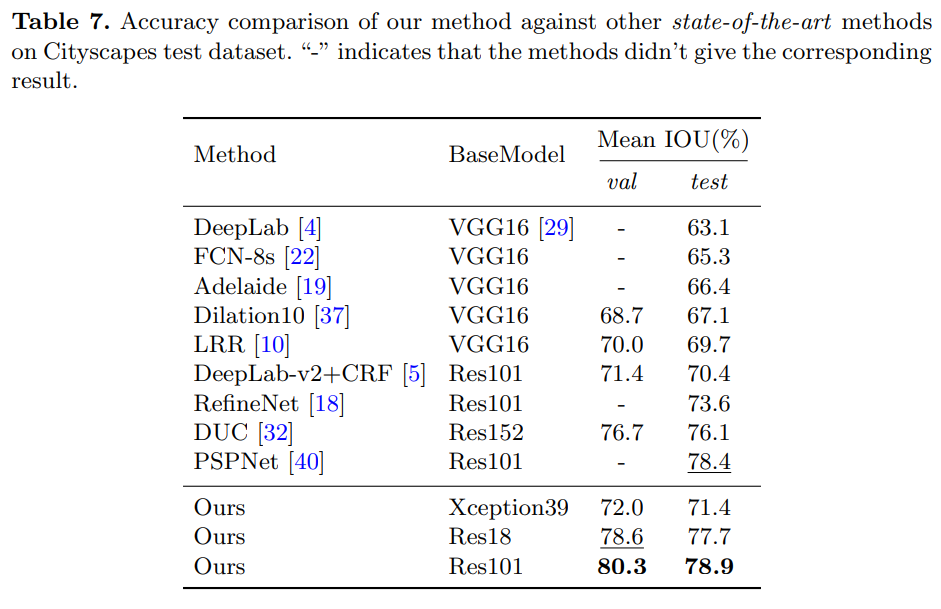
- 上大模型精度也是顶尖的
DANet
- paper Dual Attention Network for Scene Segmentation
- git https://github.com/junfu1115/DANet/
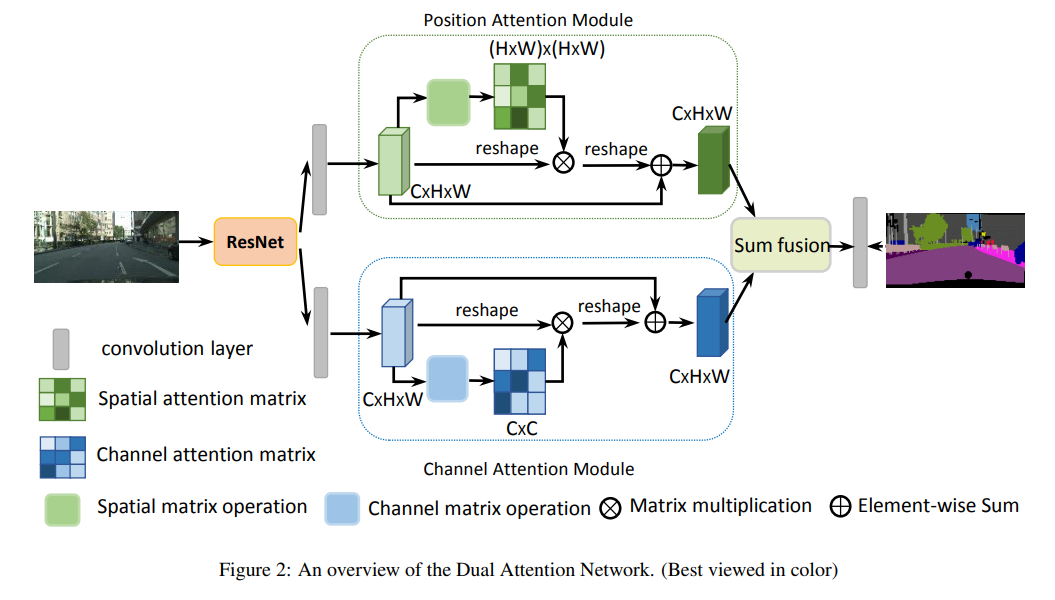
- 空间的attention 和 channel的attention 融合
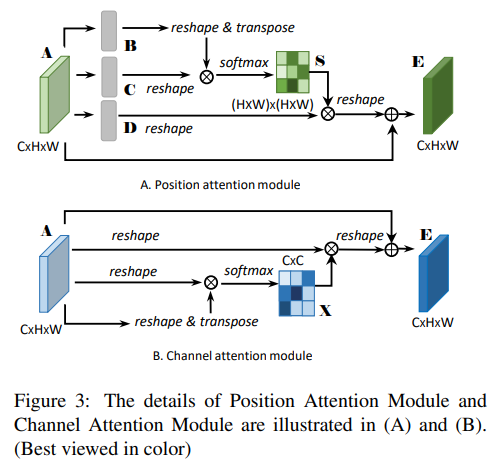
- 具体attention的做法,spatial的做法还算正常,channel的做法略有些诡异。。
- 直接上代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43class _PositionAttentionModule(nn.Module):
""" Position attention module"""
def __init__(self, in_channels, **kwargs):
super(_PositionAttentionModule, self).__init__()
self.conv_b = nn.Conv2d(in_channels, in_channels // 8, 1)
self.conv_c = nn.Conv2d(in_channels, in_channels // 8, 1)
self.conv_d = nn.Conv2d(in_channels, in_channels, 1)
self.alpha = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, _, height, width = x.size()
feat_b = self.conv_b(x).view(batch_size, -1, height * width).permute(0, 2, 1)
feat_c = self.conv_c(x).view(batch_size, -1, height * width)
attention_s = self.softmax(torch.bmm(feat_b, feat_c)) # conv transpose .* conv
feat_d = self.conv_d(x).view(batch_size, -1, height * width)
feat_e = torch.bmm(feat_d, attention_s.permute(0, 2, 1)).view(batch_size, -1, height, width) # conv .* conv transpose )reshape
out = self.alpha * feat_e + x
return out
class _ChannelAttentionModule(nn.Module):
"""Channel attention module"""
def __init__(self, **kwargs):
super(_ChannelAttentionModule, self).__init__()
self.beta = nn.Parameter(torch.zeros(1))
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
batch_size, _, height, width = x.size()
feat_a = x.view(batch_size, -1, height * width)
feat_a_transpose = x.view(batch_size, -1, height * width).permute(0, 2, 1)
attention = torch.bmm(feat_a, feat_a_transpose) # x = x * x transpose
attention_new = torch.max(attention, dim=-1, keepdim=True)[0].expand_as(attention) - attention # x.max - x
attention = self.softmax(attention_new)
feat_e = torch.bmm(attention, feat_a).view(batch_size, -1, height, width)
out = self.beta * feat_e + x
return out 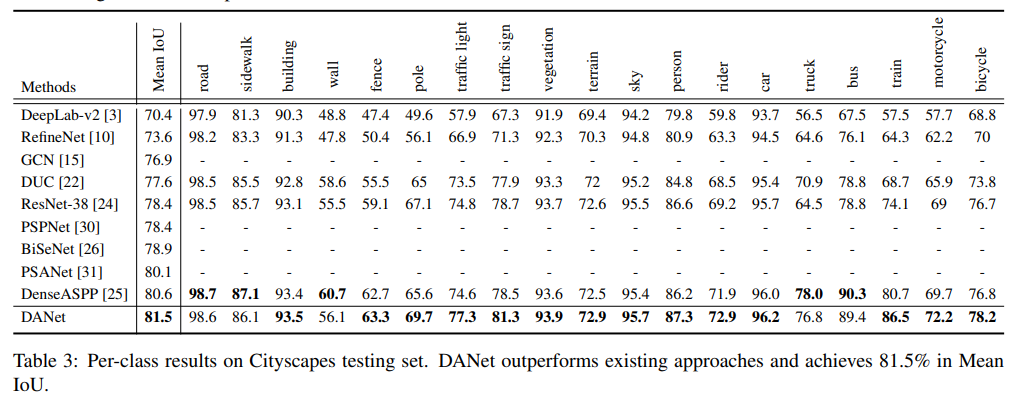
- cityscapes略强于deeplab v3的水平
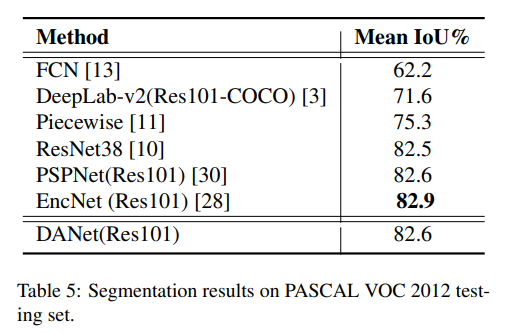
- VOC也是PSP差不多水平
CGNet
- paper CGNet: A Light-weight Context Guided Network for Semantic Segmentation
- git https://github.com/wutianyiRosun/CGNet
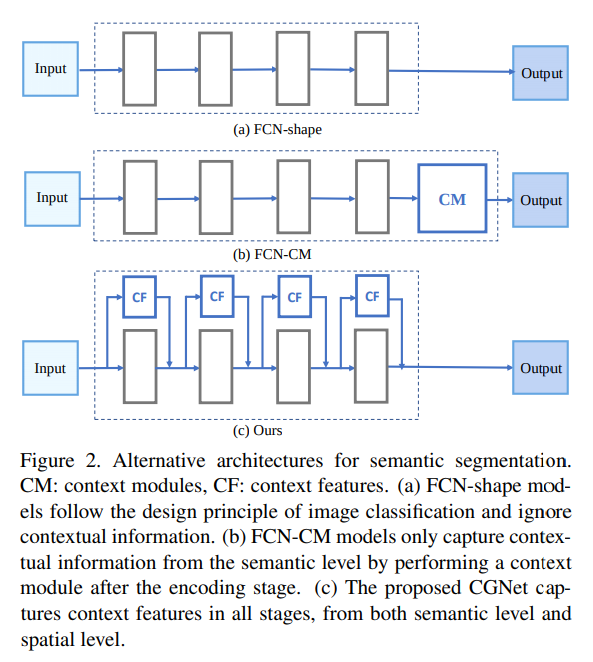
- 展示了文章的主思路。a是FCN,b是FC+context module,例如psp aspp,咱这个每个阶段都给上context Feature
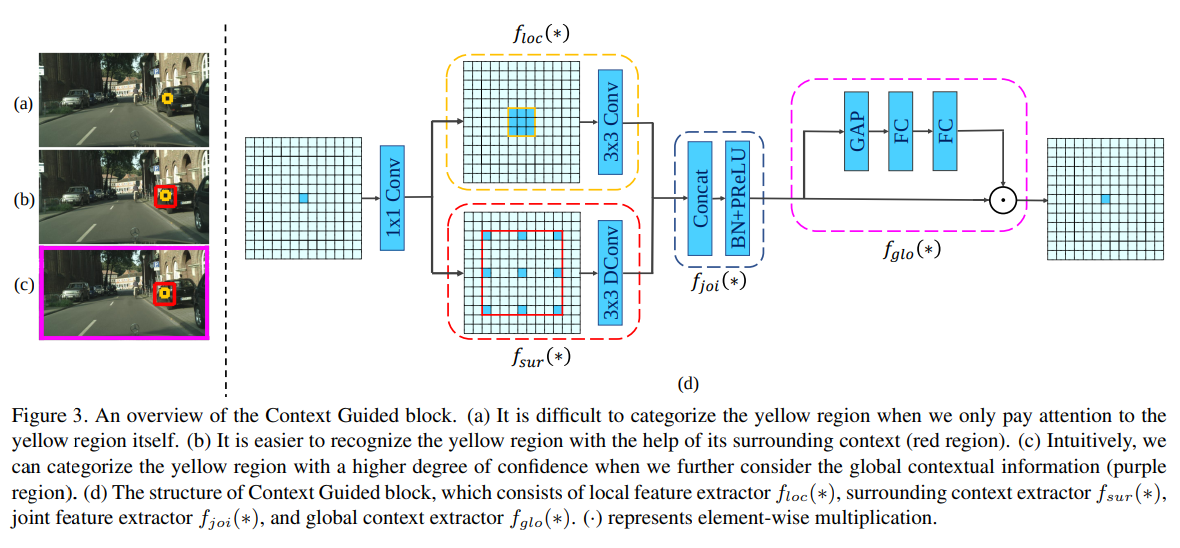
- 名字花里胡哨取一堆,就是3x3 conv和3x3 dilate=3 conv concat,然后se
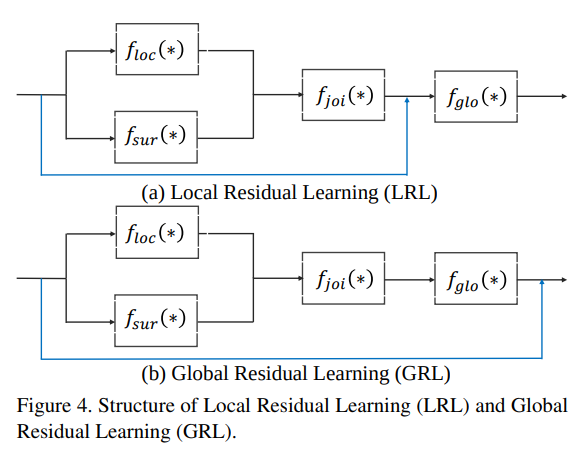
- 对module中的residual的位置也做了区分
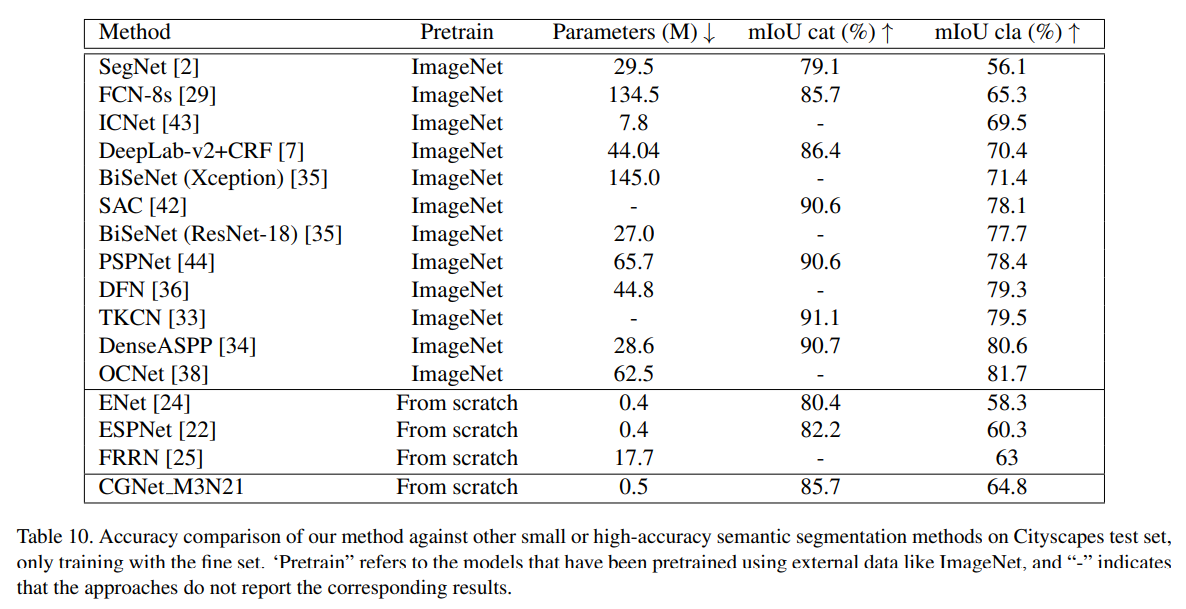
- 对标对象是 ENet ESPNet,同样参数下实现了精度 5% - 10%的进步
OCNet
- paper OCNet: Object Context Network for Scene Parsing
- git https://github.com/PkuRainBow/OCNet.pytorch
- 微软出品
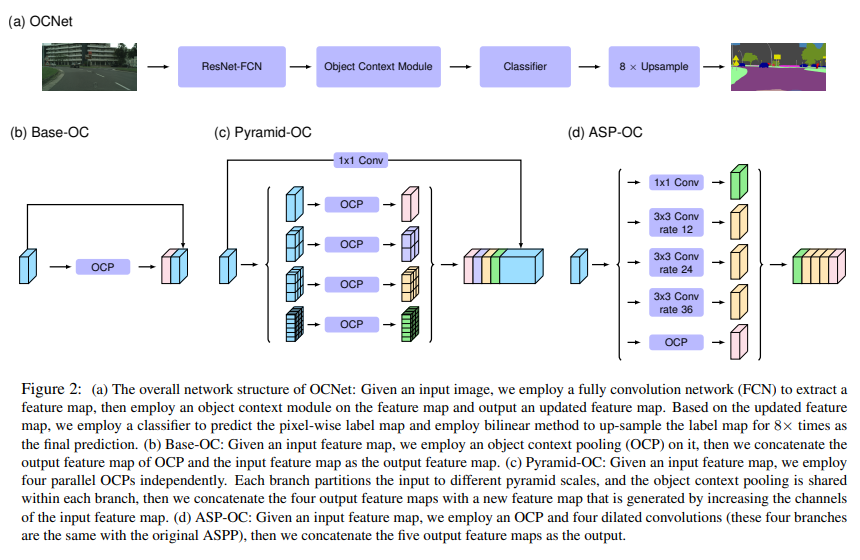
- 展示了几种OC架构,paper中并没有画出OC的基本结构,直接上代码
- OCM → BaseOC_Module OCP → BaseOC_Context_Module
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140class _SelfAttentionBlock(nn.Module):
'''
The basic implementation for self-attention block/non-local block
Input:
N X C X H X W
Parameters:
in_channels : the dimension of the input feature map
key_channels : the dimension after the key/query transform
value_channels : the dimension after the value transform
scale : choose the scale to downsample the input feature maps (save memory cost)
Return:
N X C X H X W
position-aware context features.(w/o concate or add with the input)
'''
def __init__(self, in_channels, key_channels, value_channels, out_channels=None, scale=1):
super(_SelfAttentionBlock, self).__init__()
self.scale = scale
self.in_channels = in_channels
self.out_channels = out_channels
self.key_channels = key_channels
self.value_channels = value_channels
if out_channels == None:
self.out_channels = in_channels
self.pool = nn.MaxPool2d(kernel_size=(scale, scale))
self.f_key = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=self.key_channels,
kernel_size=1, stride=1, padding=0),
InPlaceABNSync(self.key_channels),
)
self.f_query = self.f_key
self.f_value = nn.Conv2d(in_channels=self.in_channels, out_channels=self.value_channels,
kernel_size=1, stride=1, padding=0)
self.W = nn.Conv2d(in_channels=self.value_channels, out_channels=self.out_channels,
kernel_size=1, stride=1, padding=0)
nn.init.constant(self.W.weight, 0)
nn.init.constant(self.W.bias, 0)
def forward(self, x):
batch_size, h, w = x.size(0), x.size(2), x.size(3)
if self.scale > 1:
x = self.pool(x)
value = self.f_value(x).view(batch_size, self.value_channels, -1)
value = value.permute(0, 2, 1)
query = self.f_query(x).view(batch_size, self.key_channels, -1)
query = query.permute(0, 2, 1)
key = self.f_key(x).view(batch_size, self.key_channels, -1)
sim_map = torch.matmul(query, key)
sim_map = (self.key_channels**-.5) * sim_map
sim_map = F.softmax(sim_map, dim=-1)
context = torch.matmul(sim_map, value)
context = context.permute(0, 2, 1).contiguous()
context = context.view(batch_size, self.value_channels, *x.size()[2:])
context = self.W(context)
if self.scale > 1:
if torch_ver == '0.4':
context = F.upsample(input=context, size=(h, w), mode='bilinear', align_corners=True)
elif torch_ver == '0.3':
context = F.upsample(input=context, size=(h, w), mode='bilinear')
return context
class SelfAttentionBlock2D(_SelfAttentionBlock):
def __init__(self, in_channels, key_channels, value_channels, out_channels=None, scale=1):
super(SelfAttentionBlock2D, self).__init__(in_channels,
key_channels,
value_channels,
out_channels,
scale)
class BaseOC_Module(nn.Module):
"""
Implementation of the BaseOC module
Parameters:
in_features / out_features: the channels of the input / output feature maps.
dropout: we choose 0.05 as the default value.
size: you can apply multiple sizes. Here we only use one size.
Return:
features fused with Object context information.
"""
def __init__(self, in_channels, out_channels, key_channels, value_channels, dropout, sizes=([1])):
super(BaseOC_Module, self).__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(in_channels, out_channels, key_channels, value_channels, size) for size in sizes])
self.conv_bn_dropout = nn.Sequential(
nn.Conv2d(2*in_channels, out_channels, kernel_size=1, padding=0),
InPlaceABNSync(out_channels),
nn.Dropout2d(dropout)
)
def _make_stage(self, in_channels, output_channels, key_channels, value_channels, size):
return SelfAttentionBlock2D(in_channels,
key_channels,
value_channels,
output_channels,
size)
def forward(self, feats):
priors = [stage(feats) for stage in self.stages]
context = priors[0]
for i in range(1, len(priors)):
context += priors[i]
output = self.conv_bn_dropout(torch.cat([context, feats], 1))
return output
class BaseOC_Context_Module(nn.Module):
"""
Output only the context features.
Parameters:
in_features / out_features: the channels of the input / output feature maps.
dropout: specify the dropout ratio
fusion: We provide two different fusion method, "concat" or "add"
size: we find that directly learn the attention weights on even 1/8 feature maps is hard.
Return:
features after "concat" or "add"
"""
def __init__(self, in_channels, out_channels, key_channels, value_channels, dropout, sizes=([1])):
super(BaseOC_Context_Module, self).__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(in_channels, out_channels, key_channels, value_channels, size) for size in sizes])
self.conv_bn_dropout = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, padding=0),
InPlaceABNSync(out_channels),
)
def _make_stage(self, in_channels, output_channels, key_channels, value_channels, size):
return SelfAttentionBlock2D(in_channels,
key_channels,
value_channels,
output_channels,
size)
def forward(self, feats):
priors = [stage(feats) for stage in self.stages]
context = priors[0]
for i in range(1, len(priors)):
context += priors[i]
output = self.conv_bn_dropout(context)
return output - 可以得出结论,所谓OC module就是常见的spatial attention的改装
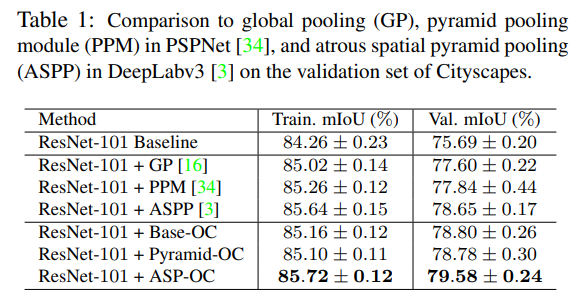
- 可以看出ASPP的结构加上OC还是有不少提升的
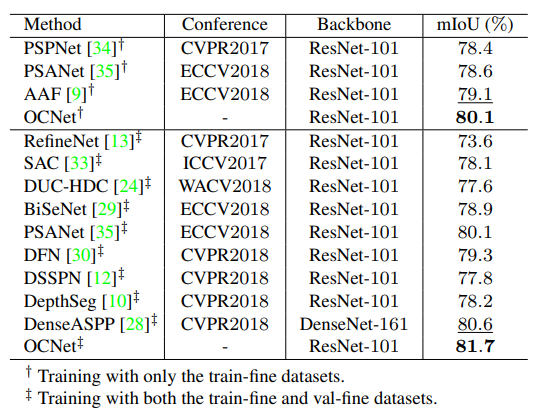
- 尽管改动简单,但是效果拔群
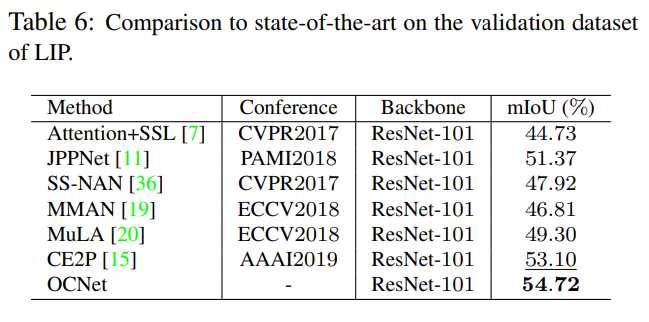
- 在LIP上也做了实验,效果也很好
DUNet
- paper Decoders Matter for Semantic Segmentation: Data-Dependent Decoding Enables Flexible Feature Aggregation
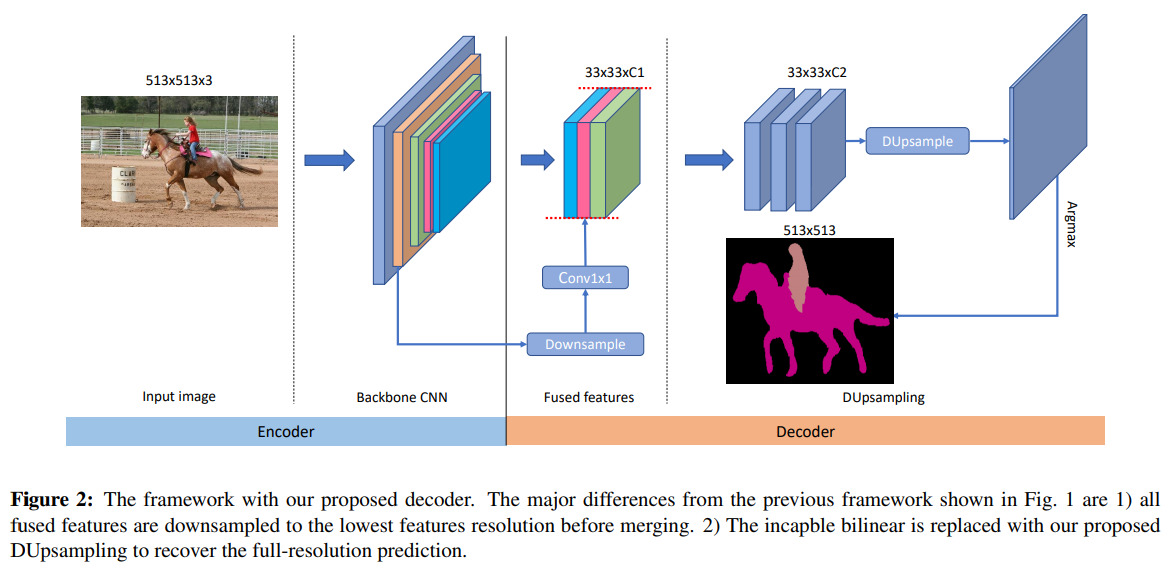
- 整体架构是个常规操作,看看DUpsample怎么玩
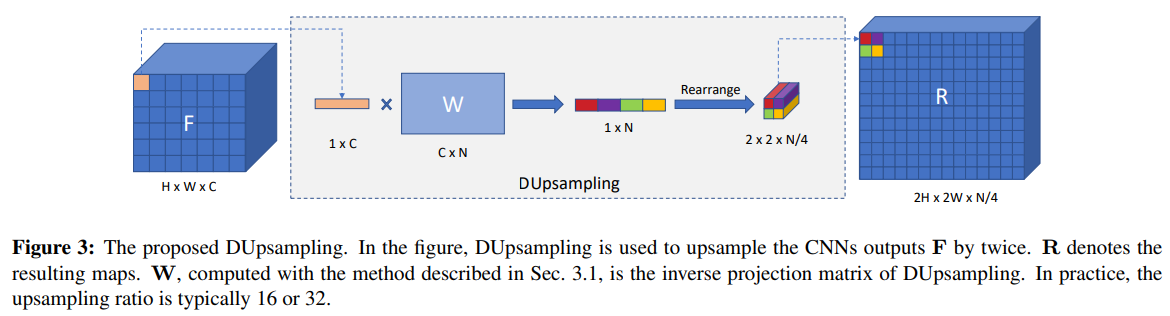
- 我觉得这个图不是很直白,直接上代码
- 整体就是 conv c → cfactorfactor,然后reshape reshape
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28class DUpsampling(nn.Module):
"""DUsampling module"""
def __init__(self, in_channels, out_channels, scale_factor=2, **kwargs):
super(DUpsampling, self).__init__()
self.scale_factor = scale_factor
self.conv_w = nn.Conv2d(in_channels, out_channels * scale_factor * scale_factor, 1, bias=False)
def forward(self, x):
x = self.conv_w(x)
n, c, h, w = x.size()
# N, C, H, W --> N, W, H, C
x = x.permute(0, 3, 2, 1).contiguous()
# N, W, H, C --> N, W, H * scale, C // scale
x = x.view(n, w, h * self.scale_factor, c // self.scale_factor)
# N, W, H * scale, C // scale --> N, H * scale, W, C // scale
x = x.permute(0, 2, 1, 3).contiguous()
# N, H * scale, W, C // scale --> N, H * scale, W * scale, C // (scale ** 2)
x = x.view(n, h * self.scale_factor, w * self.scale_factor, c // (self.scale_factor * self.scale_factor))
# N, H * scale, W * scale, C // (scale ** 2) -- > N, C // (scale ** 2), H * scale, W * scale
x = x.permute(0, 3, 1, 2)
return x 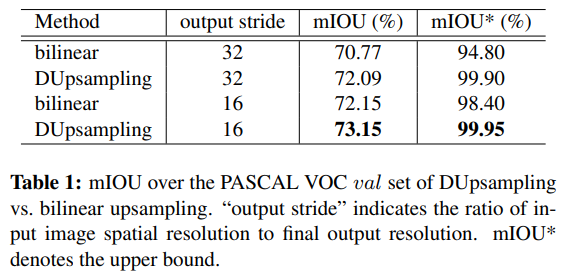
- 在voc 上进行对比,dusample相对bilinear upsample确有其优势
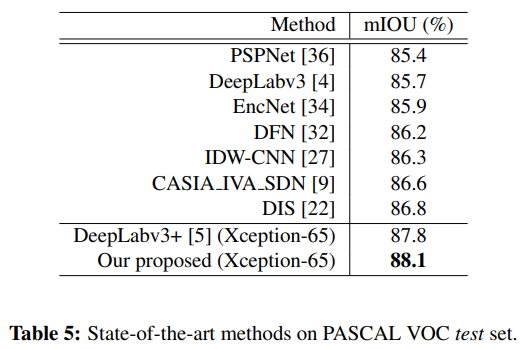
- 这个方法在deeplab v3+上一样有效,提升了0.3%
fastFCN
- paper FastFCN: Rethinking Dilated Convolution in the Backbone for Semantic Segmentation
- git https://github.come/wuhuikai/FastFCN
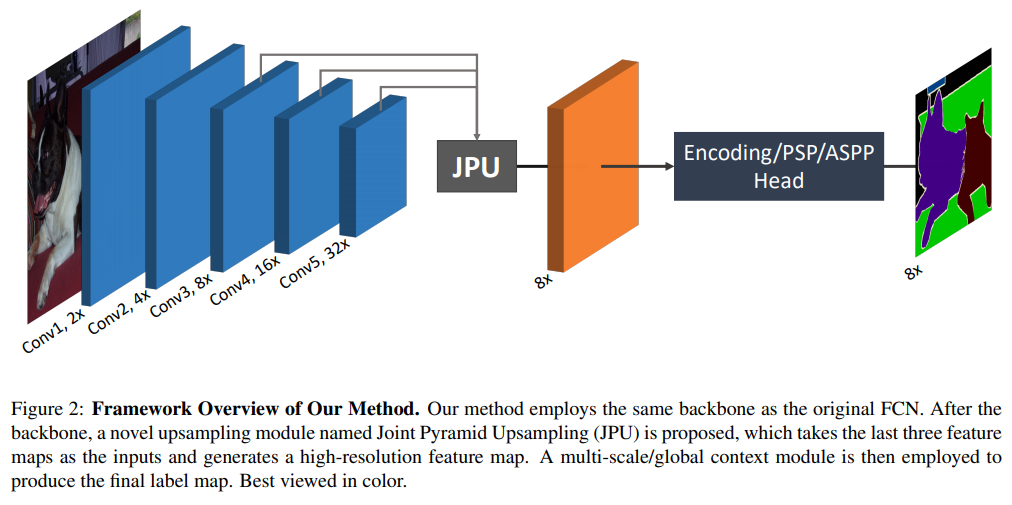
- 标准的结构,主要在JPU
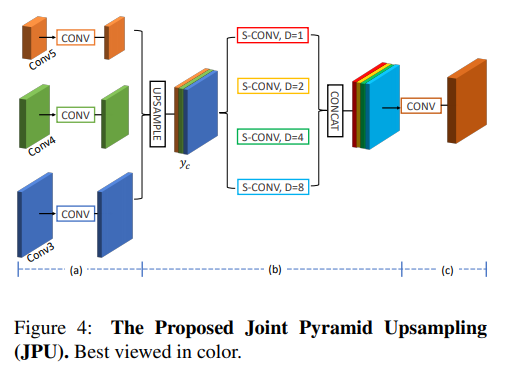
- 上采样到8X,使用多dilate进行conv,cat conv 得到结果。。。岂不是要在8x上aspp???那fast在哪呢
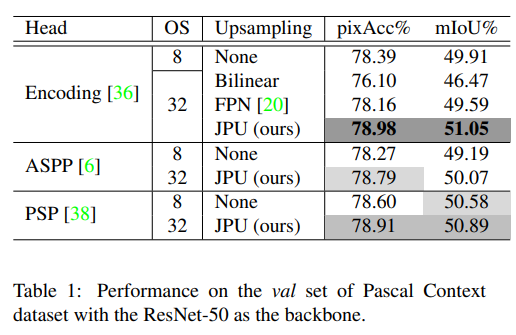
- 效果略有提升
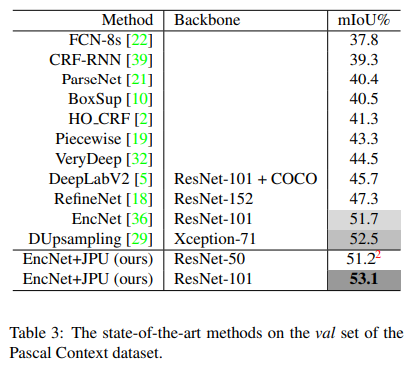
- 配合EncNet效果不错
LEDNET
- paper LEDNET: A LIGHTWEIGHT ENCODER-DECODER NETWORK FOR REAL-TIME SEMANTIC SEGMENTATION
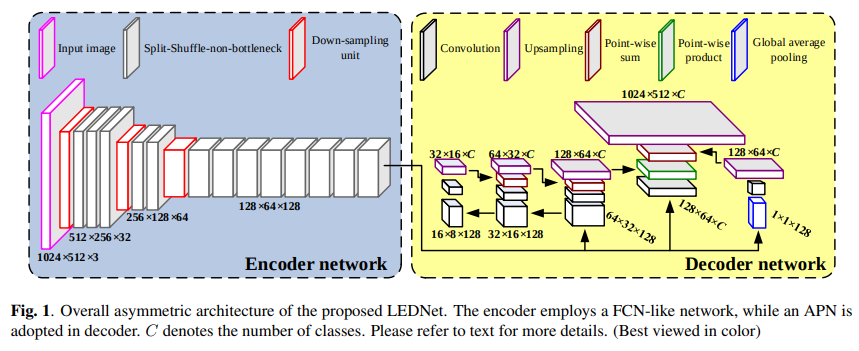
- 主要的骚操作在decode部分
Fast-SCNN
- paper Fast-SCNN: Fast Semantic Segmentation Network
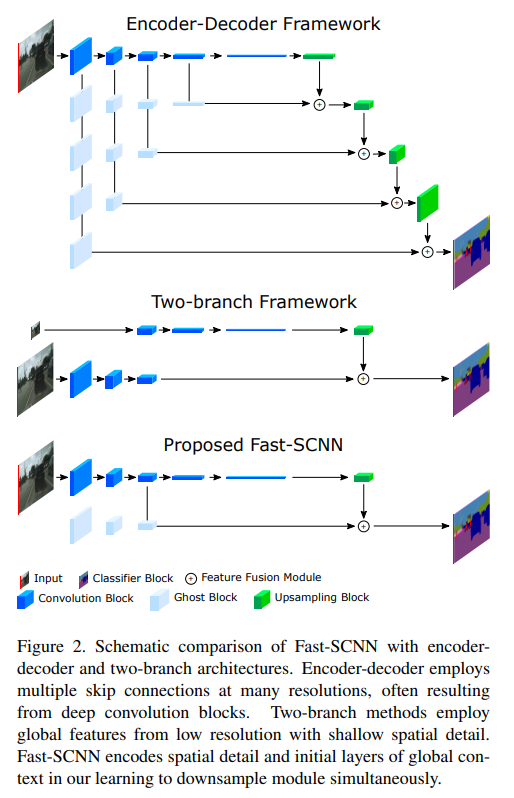
- 感觉就是deeplab v3+去掉aspp
HRNet
- paper High-Resolution Representations for Labeling Pixels and Regions
- git https://github.com/HRNet
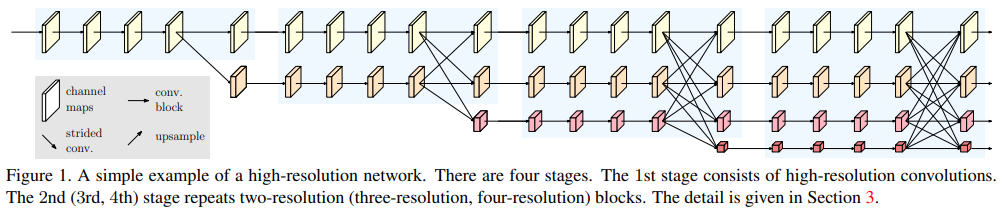
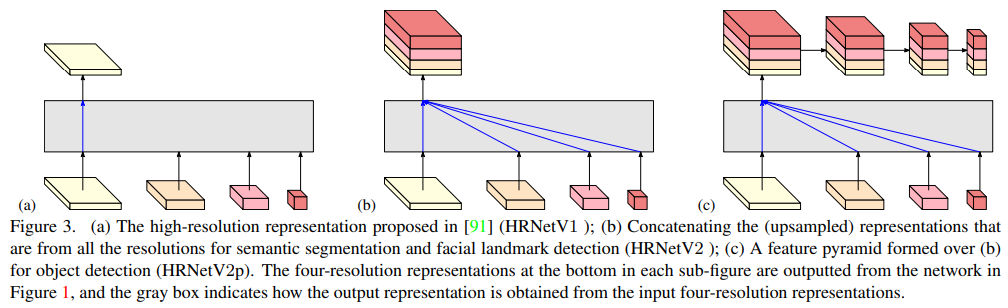
- HRNet在seg上确实是unstoppable,结构大家也都是很了解了
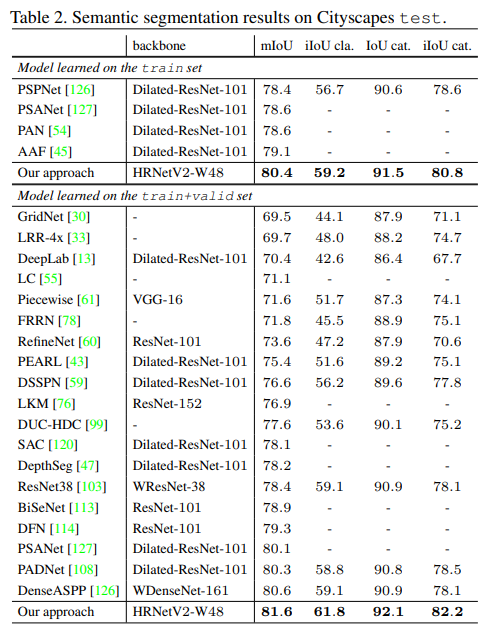
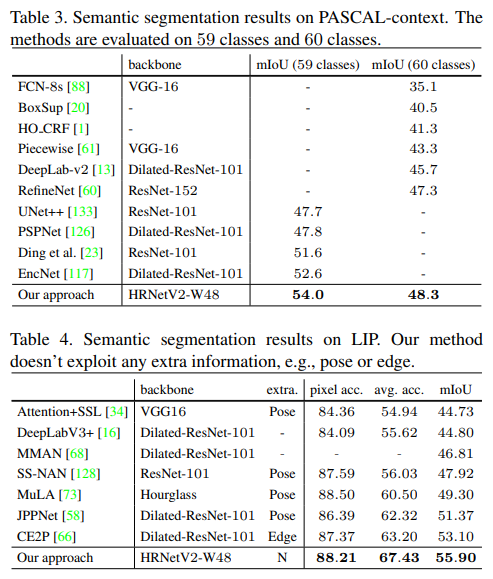
- 在LIP上,没有extra监督信息的情况下达到了55.9,相当高
DFANet
- paper DFANet: Deep Feature Aggregation for Real-Time Semantic Segmentation
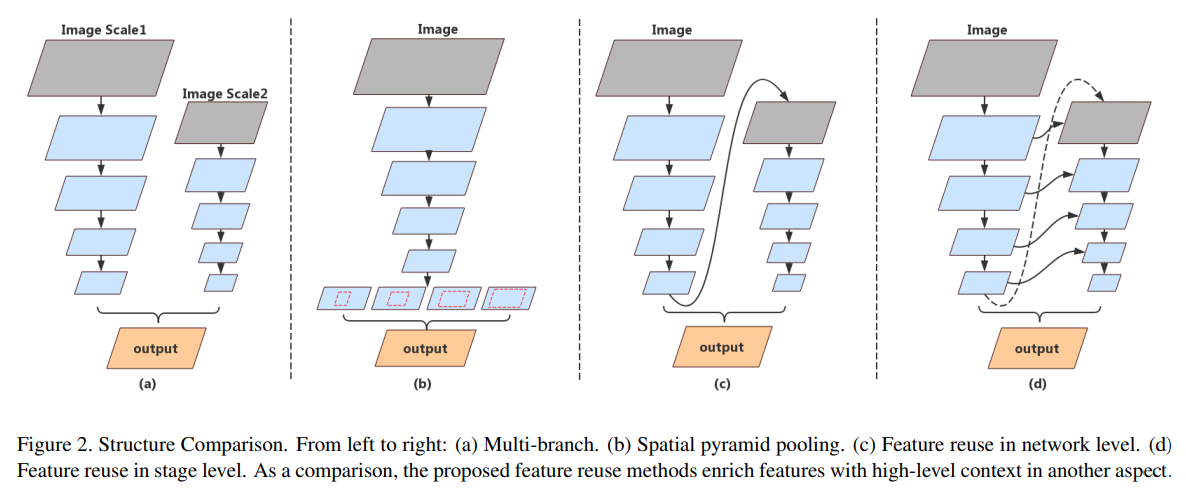
- 列举了不同的structure
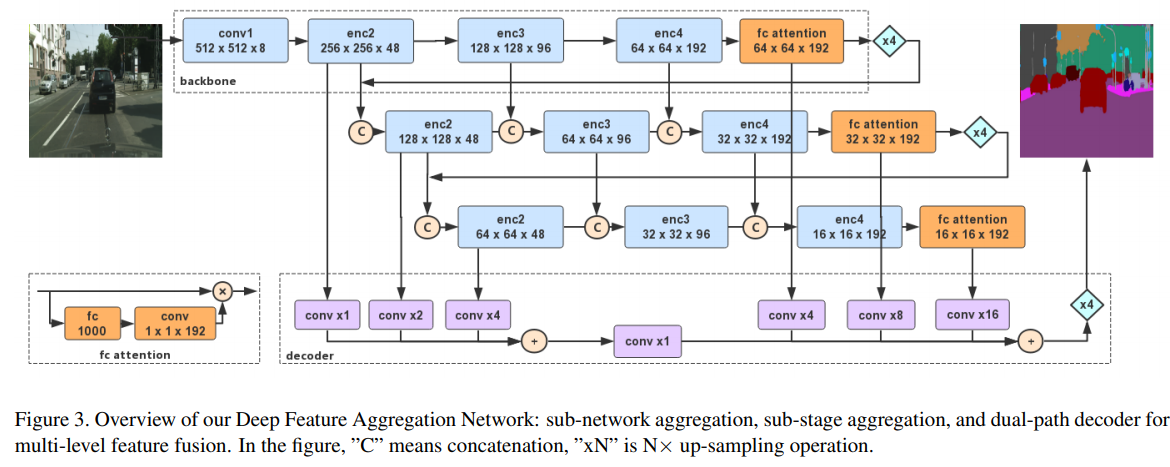
- 看起来就像是三个重复的网络在concat,和HRNet神似
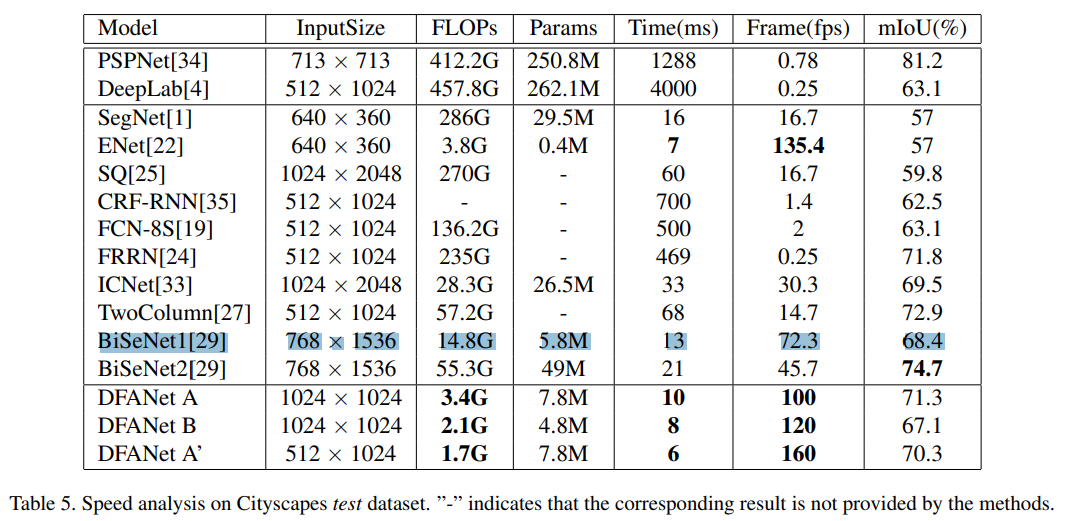
- 优势在于网络架整体深度的降低带来的计算的快速,在100fps的场景是最好的选择
OCRNet
- paper Object-Contextual Representations for Semantic Segmentation
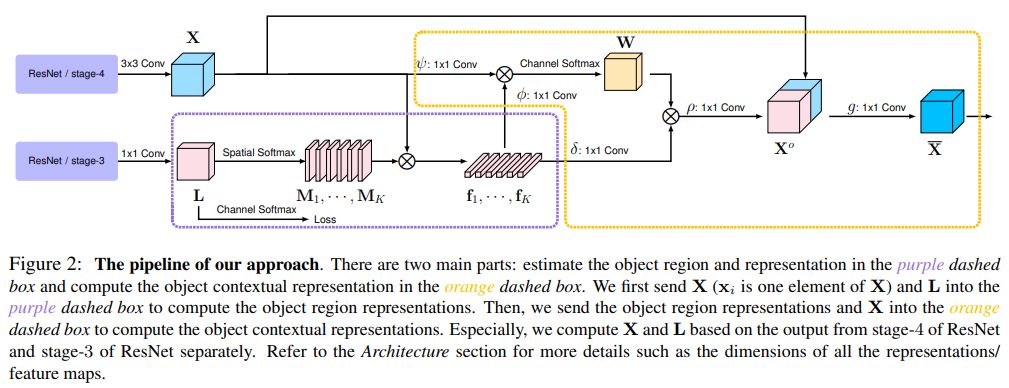
- 目前没有源代码,对其中的具体操作还有待商榷
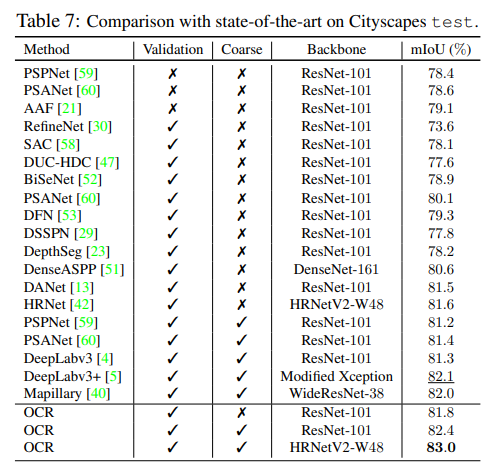
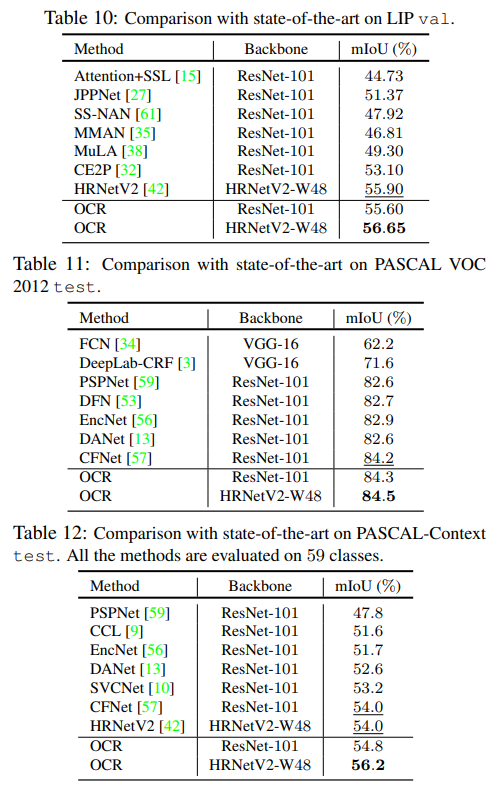
- 效果令人震惊,就坐等爸爸开源了
- It can be seen that our approach (HRNetV2 + OCR) achieves very competitive performance w/o using the video information or depth information. We then combine our OCR with ASPP [4] by replacing the global average pooling with our OCR, which (HRNetV2 + OCR (w/ ASP)) achieves 1st on 1 metric and 2nd on 3 of the 4 metrics with only a single model.
- 还说到了,如果和ASPP一起使用,将GAP换成OCR即可效果拔群
Instance Segmentation
相信说,instance seg 的deep风潮是从mask-rcnn开始的
Mask-RCNN
- paper Mask R-CNN
- git
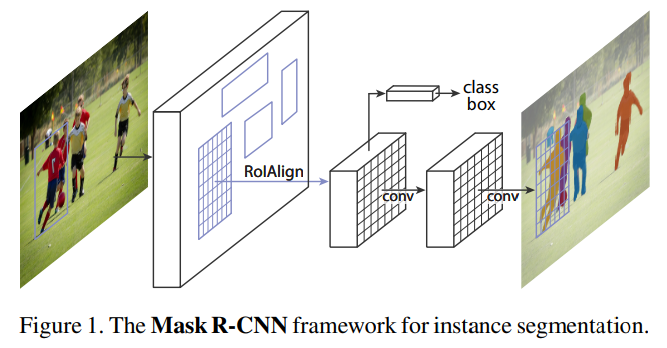
- 主体架构图

- 将RoiPooling改进为RoiAlign,从单纯的max到bilinear interpolation
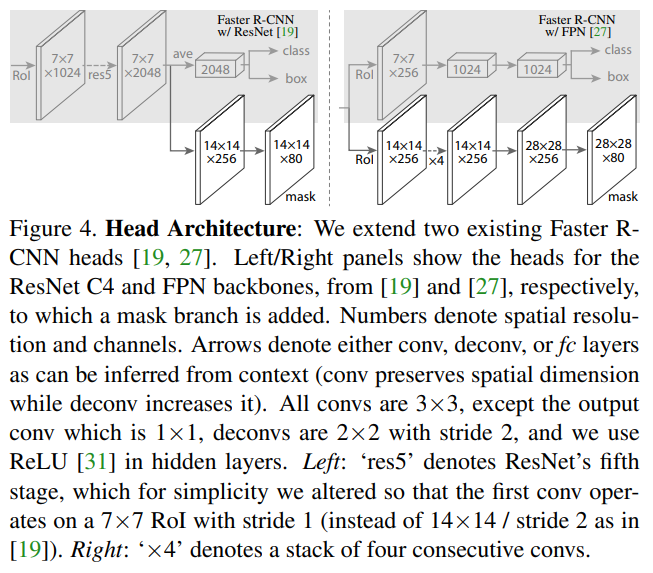
- 展示了面对FRRCNN和FRRCNN w/FPN时略有不同的head设计
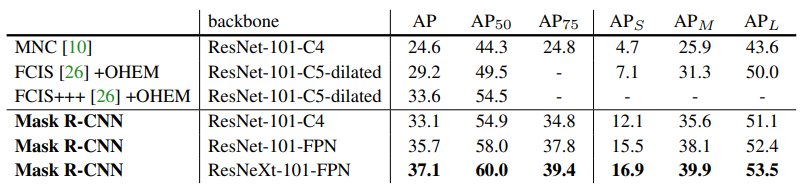
- 相较之前的结果进步巨大
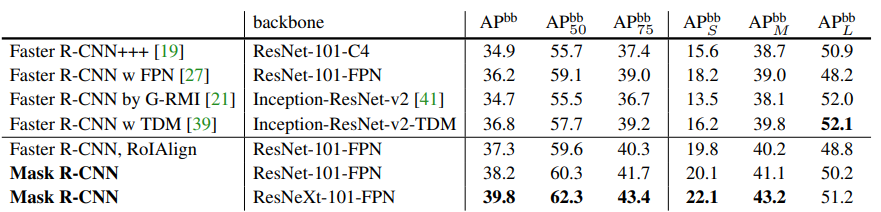
- 与此同时,就单纯拿检测效果对比,mask-RCNN的效果也明显的好过FRRCNN在使用同一个backbone的情况下
PANet
- paper Path Aggregation Network for Instance Segmentation
- git https://github.com/ShuLiu1993/PANet
- panet 也是重量级的,荣誉很多
- CVPR 2018 Spotlight paper
- 1st place of COCO Instance Segmentation Challenge 2017
- 2nd place of COCO Detection Challenge 2017
- 1st place of 2018 Scene Understanding Challenge for Autonomous Navigation in Unstructured Environments
- 相信只需要有其中一个荣誉就是重量级的了
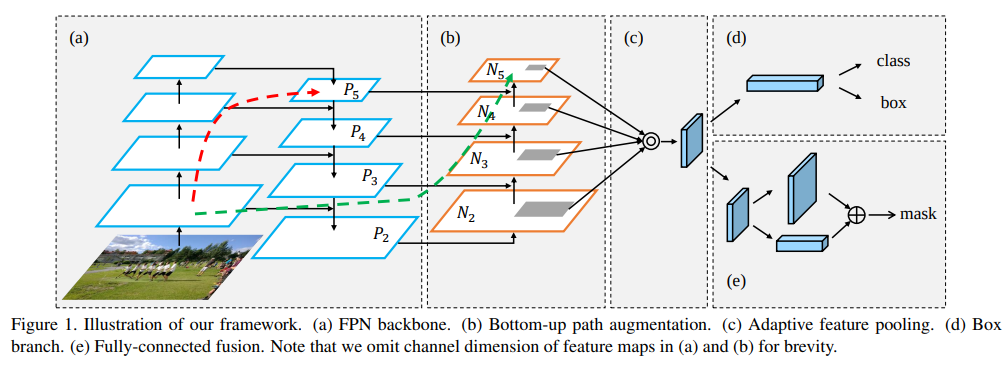
- a阶段是FPN加上一条红线,代表底层特征与高层特征的pw add;b阶段将特征再次组装,绿线作用和a阶段红线相似;c阶段进行roi pooling,将结果fuse得到结果
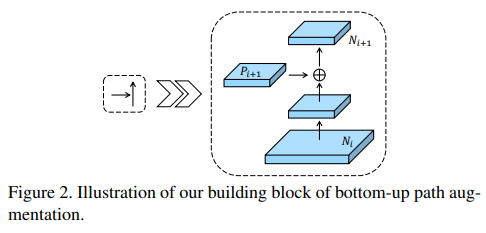
- 分拆来看,这是b阶段的细节,基本就是FPN中的upsample改为stride 2 kernel 3x3的conv
- Note that N2 is simply P2, without any processing.
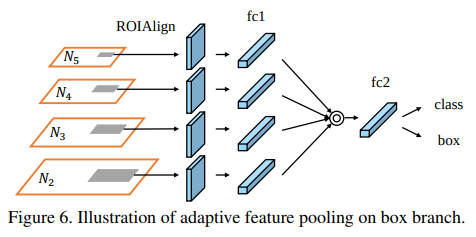
- 值得一提的是,对于多阶段的检测算法而言,各自level的roi pooling是独立进行的,但是这个图上ROI proposal都是对齐的,其实中间还有一步对齐的op,对齐后将对应的特征融合
- https://github.com/ShuLiu1993/PANet/blob/master/lib/modeling/collect_and_distribute_fpn_rpn_proposals.py
- “””Merge RPN proposals generated at multiple FPN levels and then distribute those proposals to their appropriate FPN levels. An anchor at one FPN level may predict an RoI that will map to another level, hence the need to redistribute the proposals.“”“
- 源代码中有这样一段专门用来做这个事情,简单说就是将所有的proposal给其他level都复制一份,来达到对齐
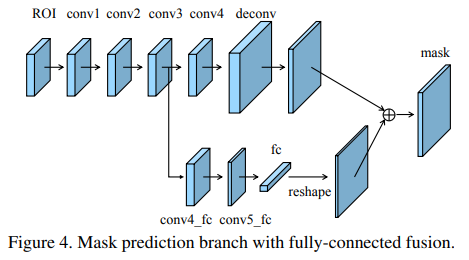
- 在mask分支作者也是使用了 conv 与 fc 结合的策略提高seg的精度

- 吊打了Mask-RCNN w/FPN,但其实也伴随着肉眼可见的计算量增加

- 在detection上也不遑多让,也是吊打
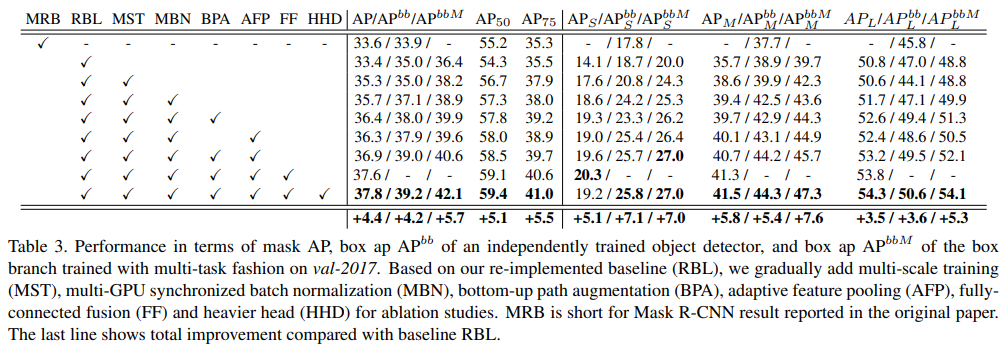
- 同时,作者在 Ablation Studies 中也复现了mask rcnn,并使用训练技巧使其涨点4.4
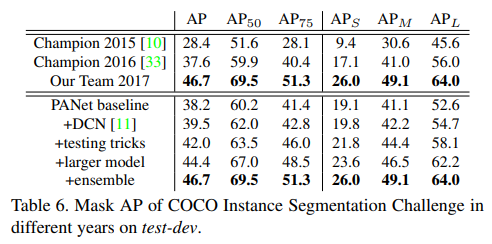
- 分享了COCO第一的方法,看得出来,这几个方法都涨点很猛
- 总结:这是一篇干货满满的文章,值得一看
MS R-CNN
- paper Mask Scoring R-CNN
- git https://github.com/zjhuang22/maskscoring_rcnn
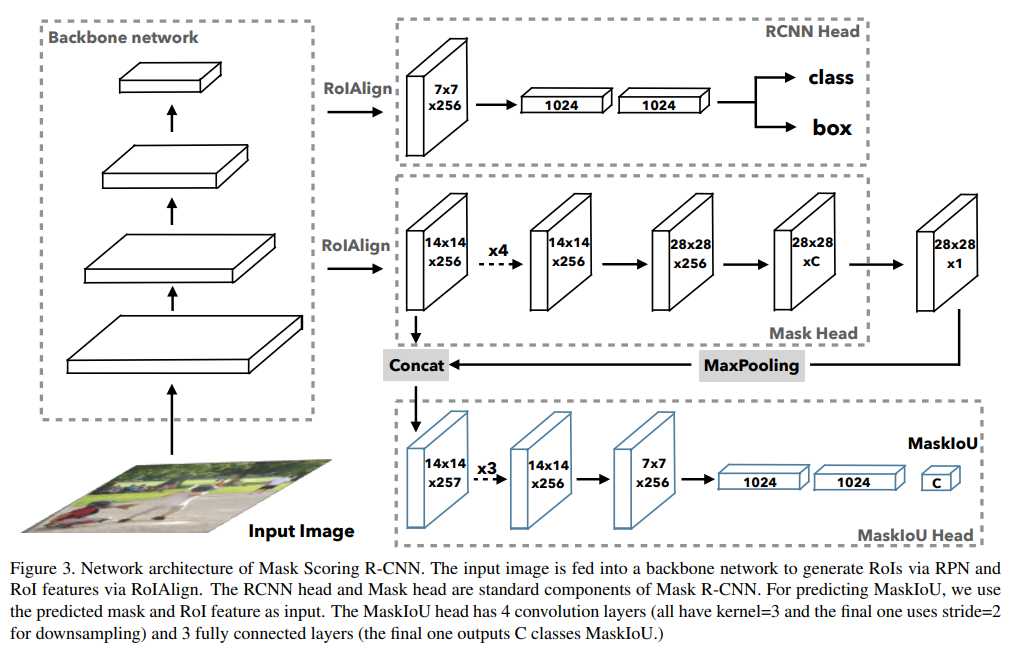
- The RCNN head and Mask head are standard components of Mask R-CNN. 新的mask iou分支用于预测各个类别的iou分值
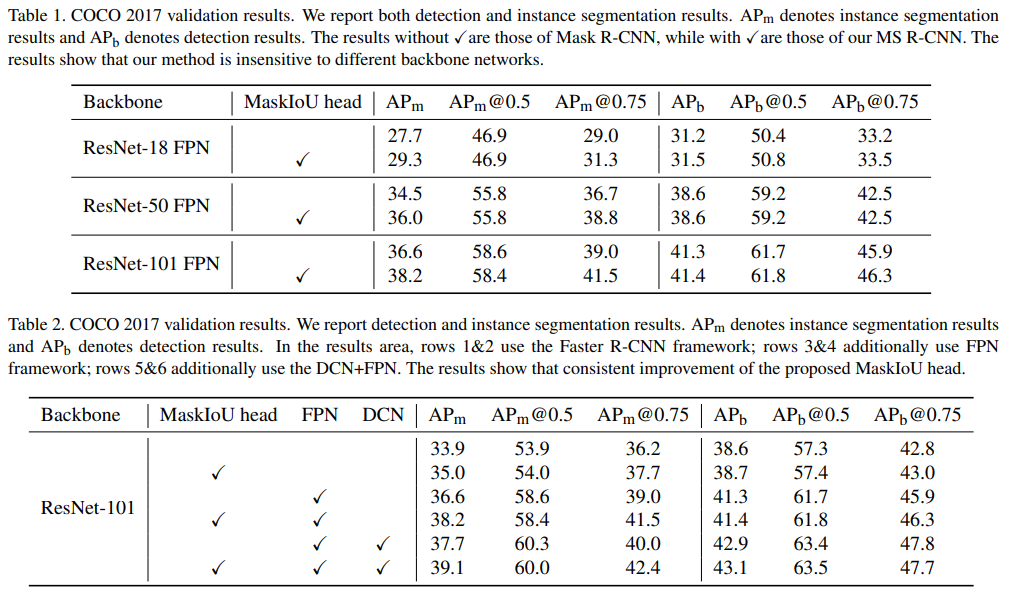
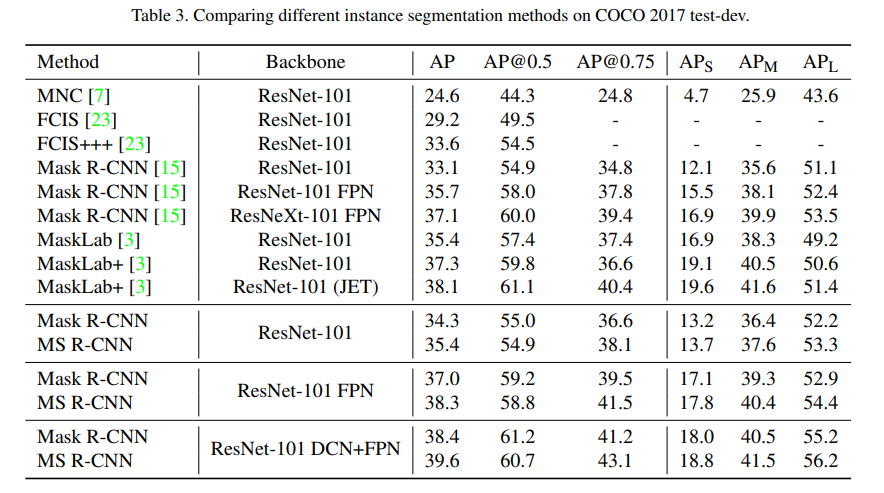
- 这样简单的操作就开始快乐涨点了,在几乎所有情况下都有效,还要啥自行车
yolact
- paper YOLACT Real-time Instance Segmentation
- git https://github.com/dbolya/yolact
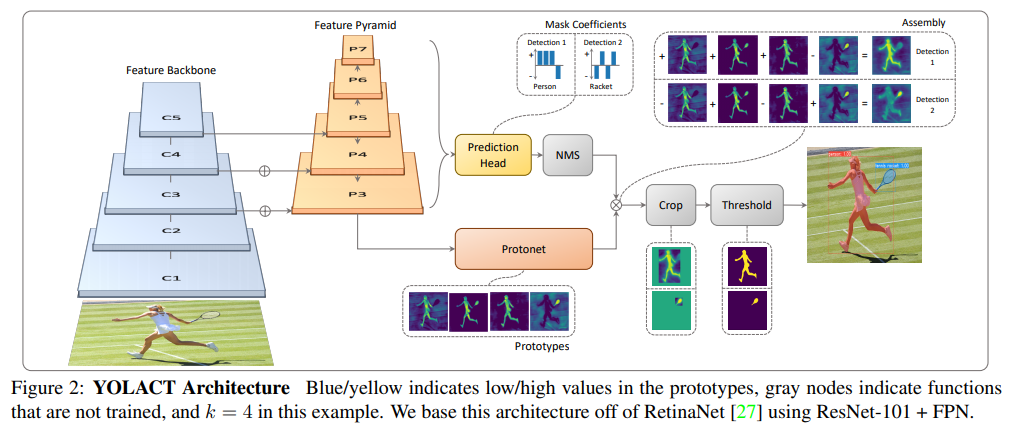
- based on retinanet. predict出bbox cls mask,经过nms,然后和protonet的结果结合得到instance的mask
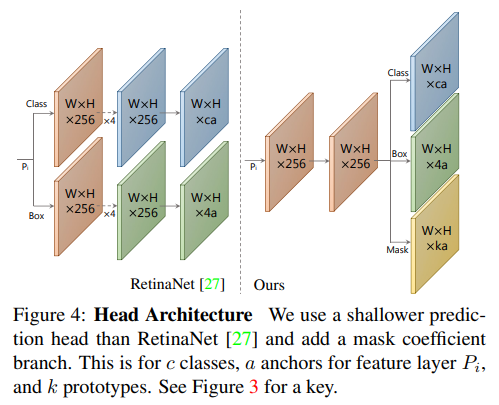
- haed略有不同,share了tower减少计算和参数,多计算了一份mask分支,mask分支的dim k是由config设置的
1
2
3
4if cfg.mask_type == mask_type.direct:
cfg.mask_dim = cfg.mask_size(16)**2
elif cfg.mask_type == mask_type.lincomb:
cfg.mask_dim = num_grids + num_features - loss: Since each pixel can be assigned to more than one class, we use sigmoid and c channels instead of softmax and c + 1. This loss is given a weight of 1 and results in a +0.4 mAP boost.
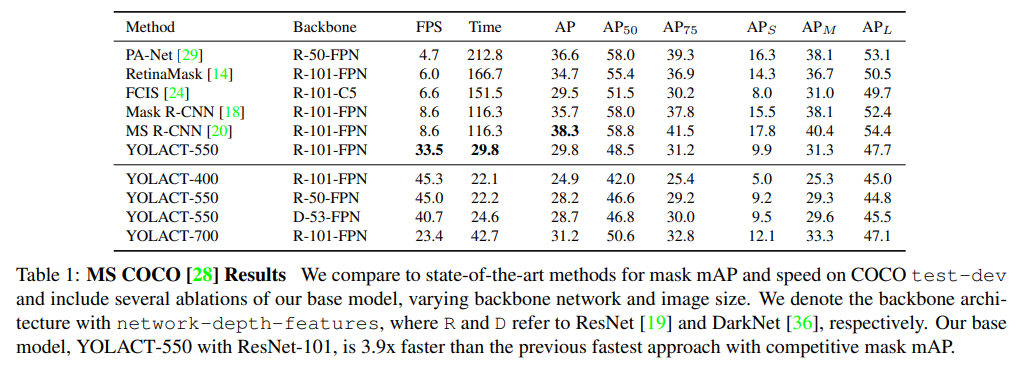
- 整体上看,精度相同的情况下速度上完全吊打了FCIS,是个realtime 不错的选择
PolarMask
- paper PolarMask: Single Shot Instance Segmentation with Polar Representation
- git https://github.com/xieenze/PolarMask
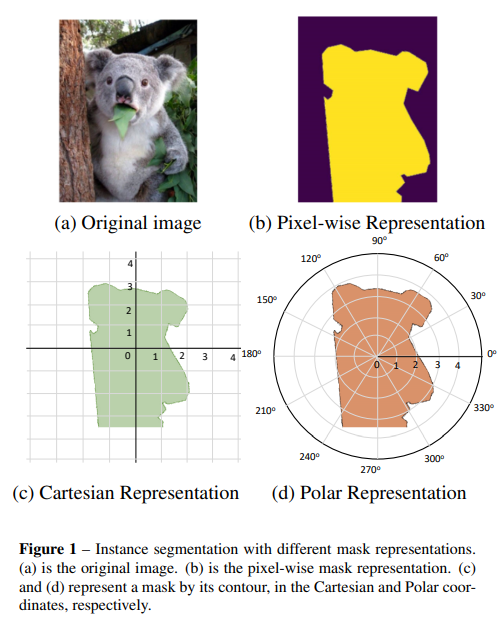
- 展示了笛卡尔系建模和极坐标系建模的detail
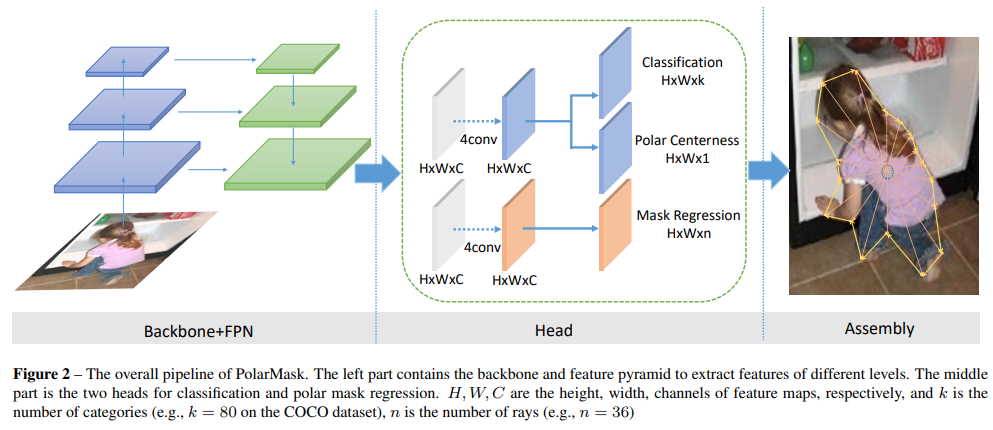
- 文章将FCOS进行了拓展,将bbox视为polar系下的4等分角度多边形,将mask视为polar系下的无线等分的多边形

- 换个方式算centerness,后面有实验证明这个centerness的优势
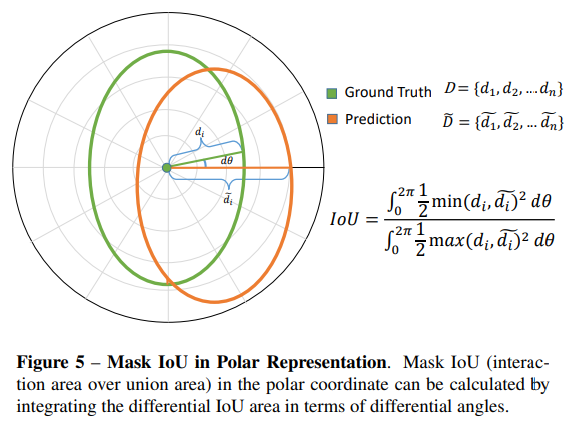
- 既然采用了polar系,iou的计算方式也要有所改变,虽然这个式是积分式,其实现实里是离散化成n等分的
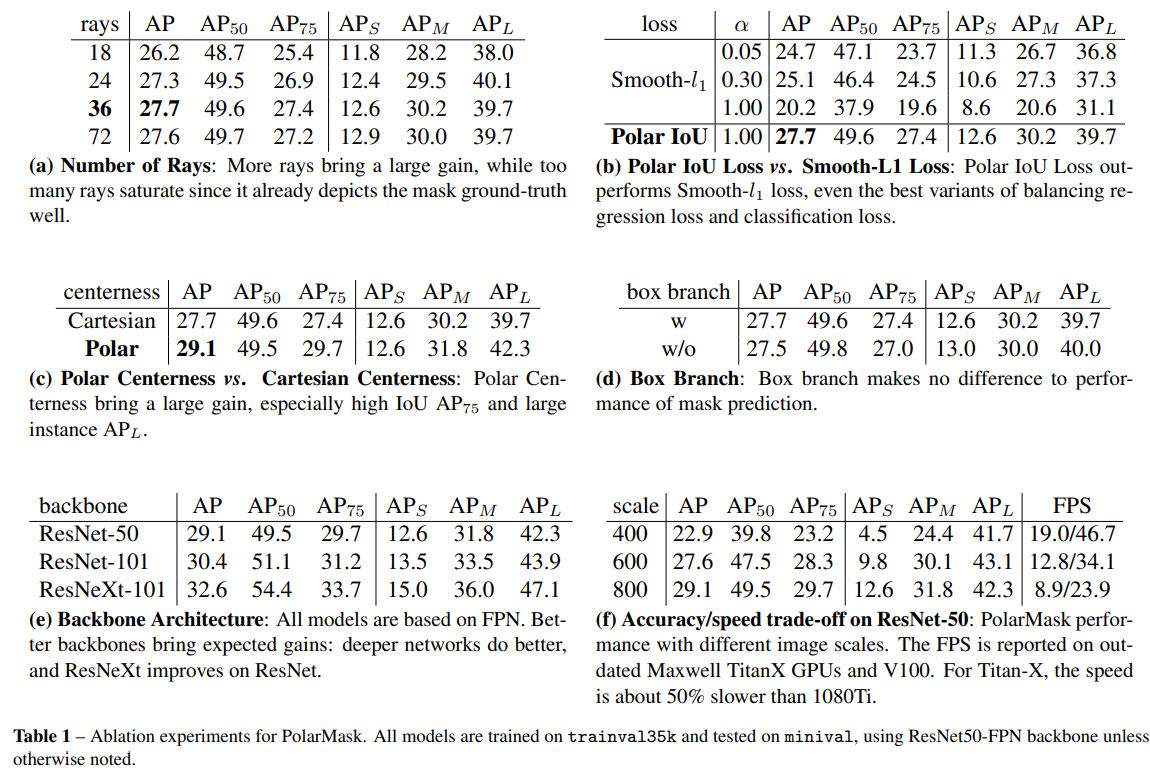
- (左 → 右 上 → 下)
- rays 代表切割的份数,实验证明切36份就差不多了
- 对比了smooth-l1 和 polar iou loss,不用iou loss真滴不行
- 使用polar centerness比卡迪尔中心更好
- box branch 有没有无所谓
- backbone还是越牛逼越好
- scale 当然也是越大越好
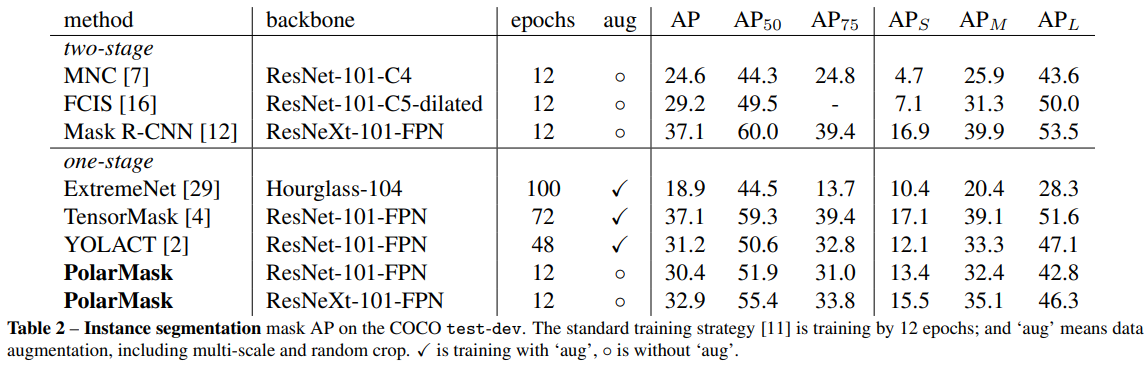
- 在仅训练12epochs w/o aug的情况下达到了30+的coco mask map
CenterMask
- paper CenterMask:Real-Time Anchor-Free Instance Segmentation
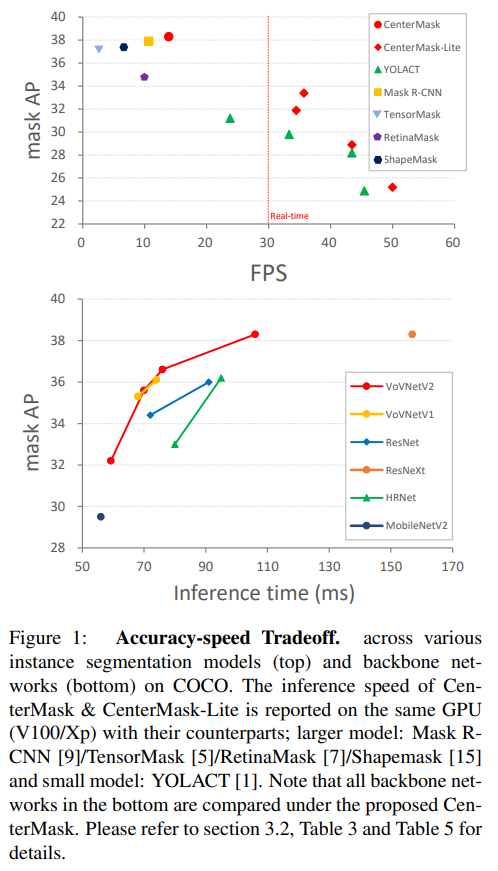
- amazing!在速度和精度上均超过了mask rcnn,而且在实时模型的pk中也大幅胜过yolact,来看看他是怎么做的
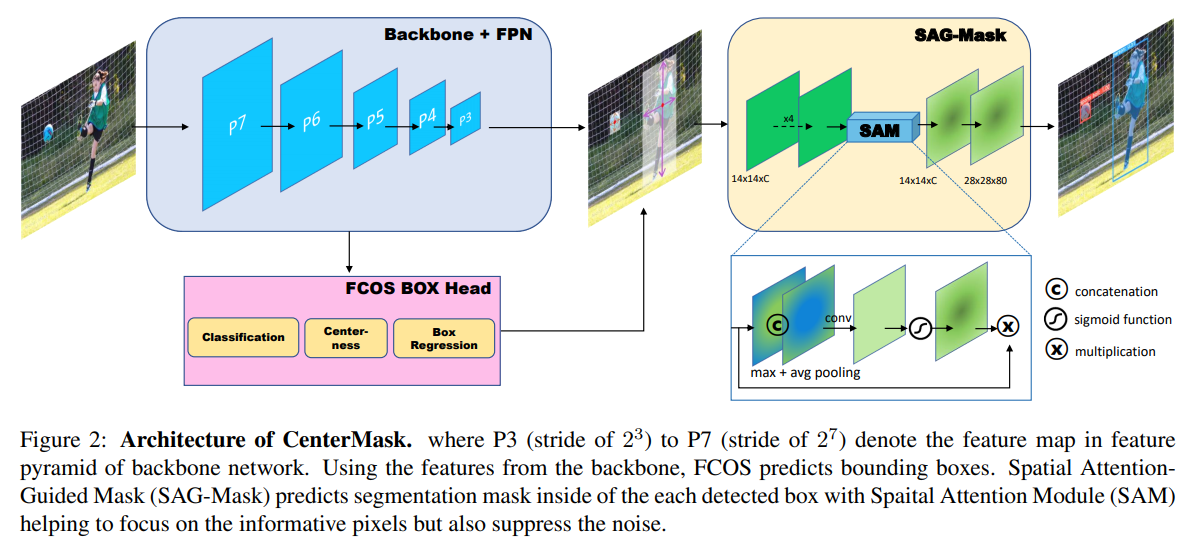
- 整体架构:使用FCOS作为类似RPN网络用于出bbox和cls,然后对每一个Bbox经过sag mask来抑制pixel层面的noise来完成mask
- 图上没有,但是作者提到了 Adaptive RoI Assignment Function 用于自适应多level, 将不同大小的box标准化到一个大小
- sam是一个 pooling + sig + elewise-mul 的 spatial attention guided mask(就是个空间attention)
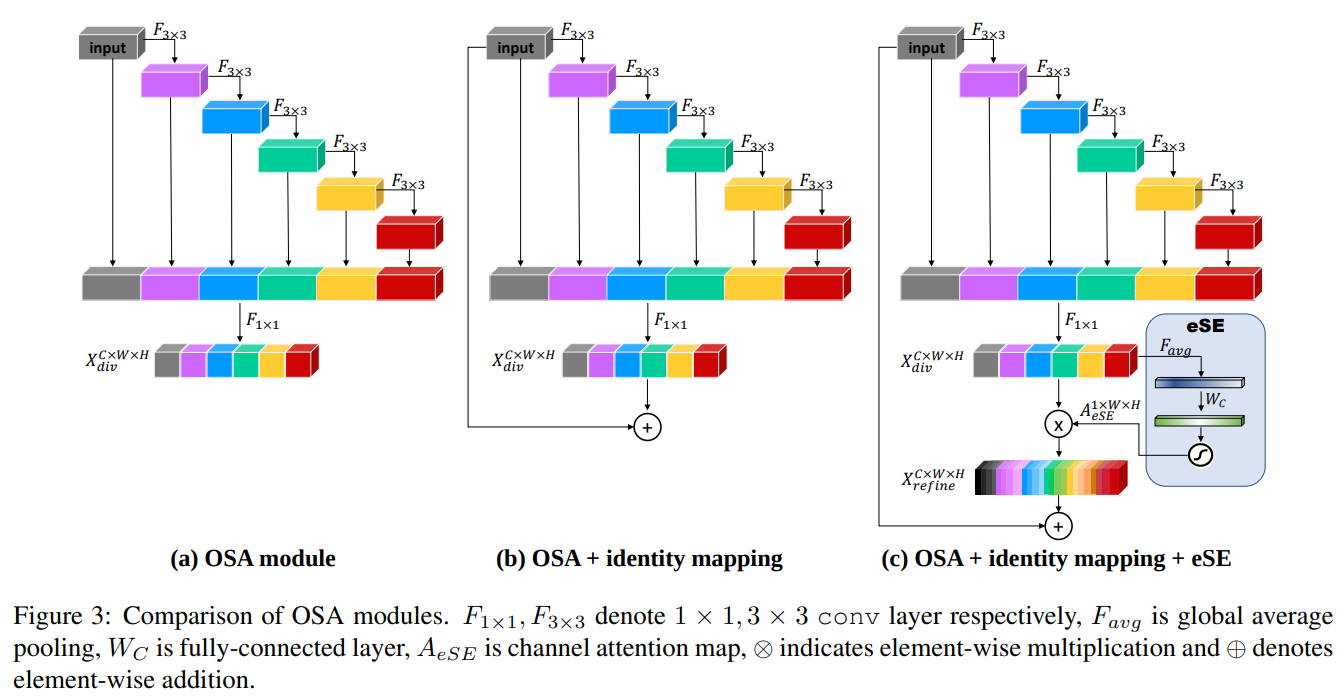
- 文中一大亮点是,提出了 VoVNet v2,提高了vovnet的性能,主要的改动在 OSA module 上
- Residual connection: 上图b
- eSE: 上图c 主要就是gap然后fc,elewise-mul (ECANet也是如此,叫法不同)
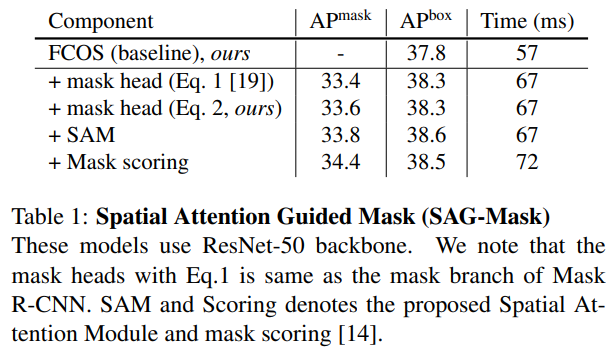
- 作者以FCOS0-R50为例,展示了将其改造为centermask的过程和时间消耗增加其中 mask scoring就是前面提到亮点ms rcnn的miou loss分支,时间消耗每图多15ms,是可接受范围
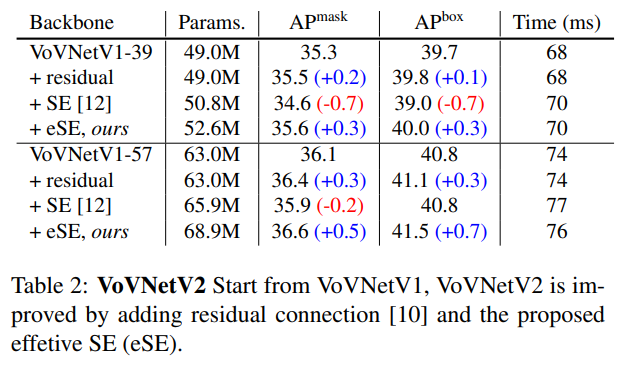
- 展示了VoVNetV2中改进的两点的效果,在时间消耗小幅增加的的前提下,精度得到了很不错的trade off
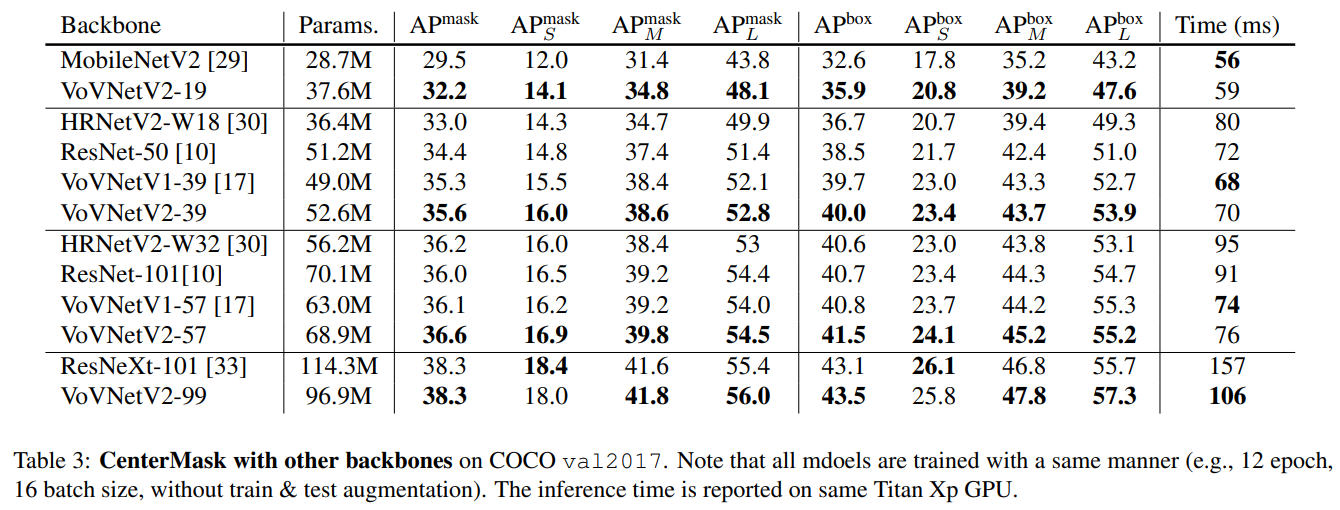
- 与现在主流的backbone: resnet resnext hrnet 做了对比,在同等精度下(或相对高一些的精度),VoVNet在CenterMask上都能在GPU上跑得更快
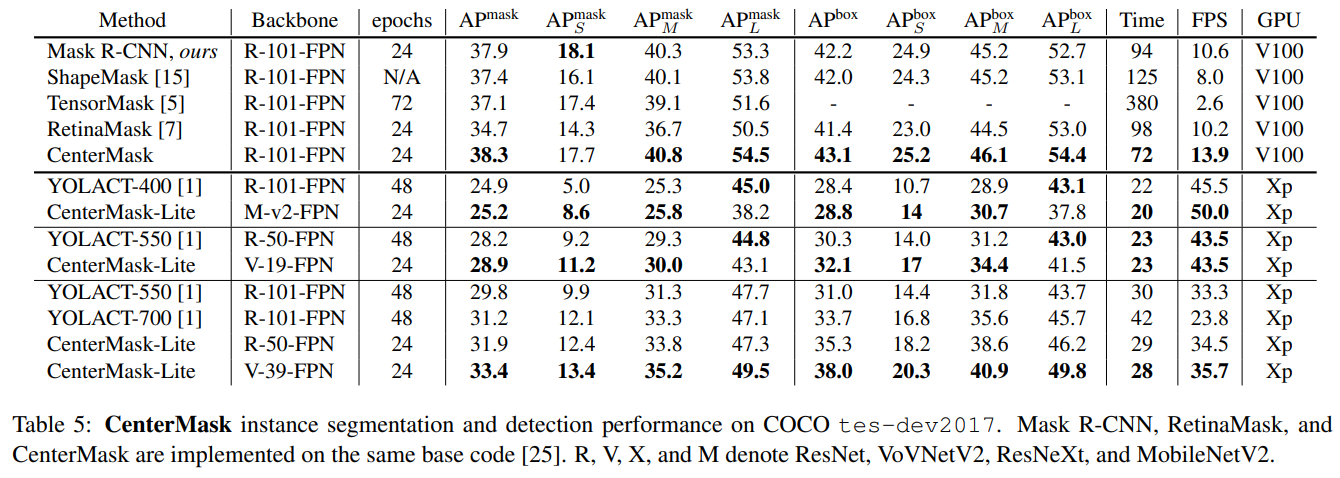
- 对比现在realtime的instance mask架构,CenterMask在同等速度下精度都能有较大提升
- 非常值得推荐的方法
dataset
Semantic Segmentation
Pascal VOC 2012
- home http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2012/index.html
- download http://host.robots.ox.ac.uk:8080/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
- 20 classes. The 2012 dataset contains images from 2008-2011 for which additional segmentations have been prepared. As in previous years the assignment to training/test sets has been maintained. The total number of images with segmentation has been increased from 7,062 to 9,993.
- VOCAug
- VOCAug 也是非常常用的数据集,由VOC变种而来
- 11355 train 2857 val
Cityscapes
- home https://www.cityscapes-dataset.com/
- download home上可以找到,需要注册账号下载
- baiduyun https://pan.baidu.com/s/1w3W_dQBUiHcwkLOtbSJ1Tg 1bln
- 30 classes. We present a new large-scale dataset that contains a diverse set of stereo video sequences recorded in street scenes from 50 different cities, with high quality pixel-level annotations of 5 000 frames in addition to a larger set of 20 000 weakly annotated frames. The dataset is thus an order of magnitude larger than similar previous attempts. Details on annotated classes and examples of our annotations are available at this webpage.
ADE20K
- home http://groups.csail.mit.edu/vision/datasets/ADE20K/
- download http://groups.csail.mit.edu/vision/datasets/ADE20K/ADE20K_2016_07_26.zip
- train 20210 val 2000 test. 类别是开放的,目前至少有250个类
Instance Segmentation
COCO 17
- home http://cocodataset.org/#download | http://cocodataset.org/#stuff-2017
- download http://cocodataset.org/#download
- 需要下载的文件较多,看到的都下载就行
- The task includes 55K COCO images (train 40K, val 5K, test-dev 5K, test-challenge 5K) with annotations for 91 stuff classes and 1 ‘other’ class. The stuff annotations cover 38M superpixels (10B pixels) with 296K stuff regions (5.4 stuff labels per image). Annotations for train and val are now available for download, while test set annotations will remain private.