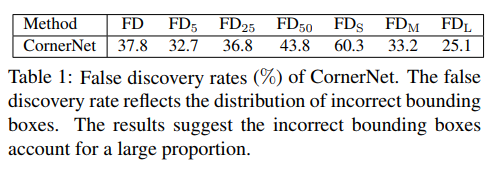
YOLO v1
- paper You Only Look Once: Unified, Real-Time Object Detection
- git https://github.com/pjreddie/darknet
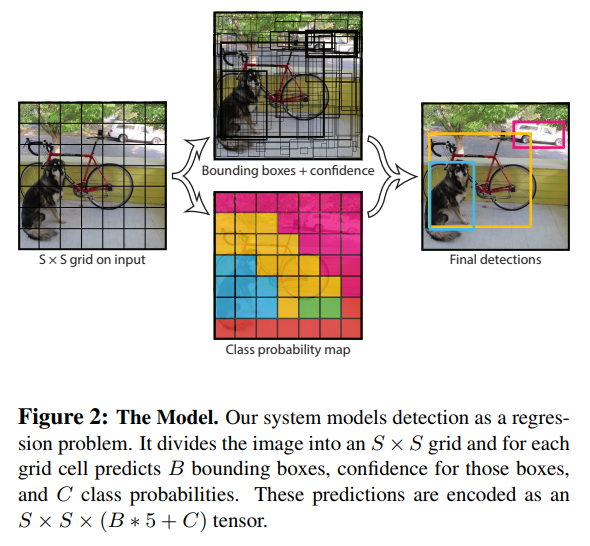

- Each grid cell predicts B bounding boxes and confidence scores for those boxes.
- Our system models detection as a regression problem. It divides the image into an S × S grid and for each grid cell predicts B bounding boxes, confidence for those boxes, and C class probabilities. These predictions are encoded as an S × S × (B ∗ 5 + C) tensor.
- For evaluating YOLO on PASCAL VOC, we use S = 7, B = 2. PASCAL VOC has 20 labelled classes so C = 20. Our final prediction is a 7 × 7 × 30 tensor.
- loss
- exp
- 现在看来简单粗暴,在当时可谓是轰动一时,方法是极具开创性的。
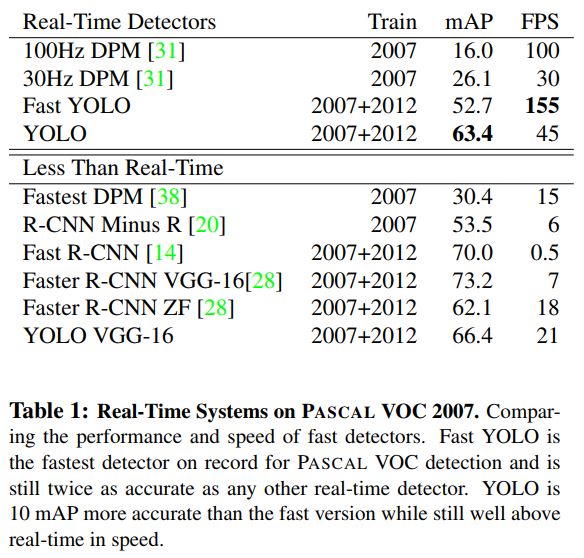
- FRRCNN的速度不敢恭维,而YOLO v1 几乎是率先达到了DEEP learning 的实时水平,虽然anchor free只是无心插柳,但也确实是anchor free。
- 但是没有anchor — 召回低,没有mu-level-feature 精度有限,backbone是darknet19,精度低
- 在这篇文章之后,这个彩虹小马哥吸取 ssd 的anchor及mul-level做法,使得yolo2 与 ssd 一时瑜亮
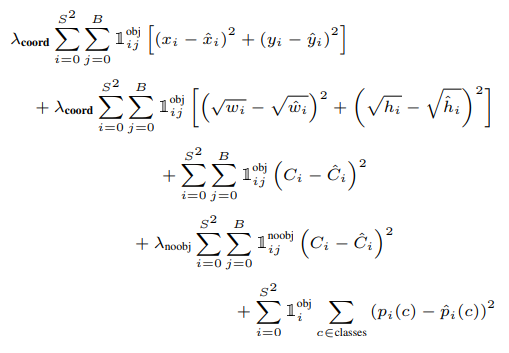
DenseBox
- paper https://arxiv.org/pdf/1509.04874.pdf
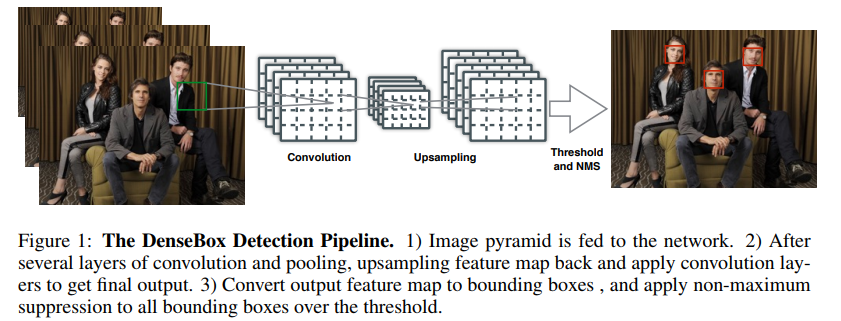
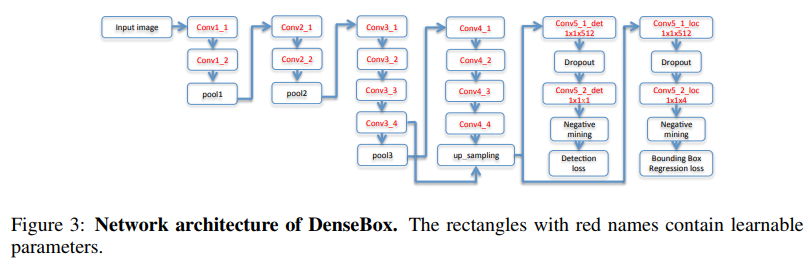
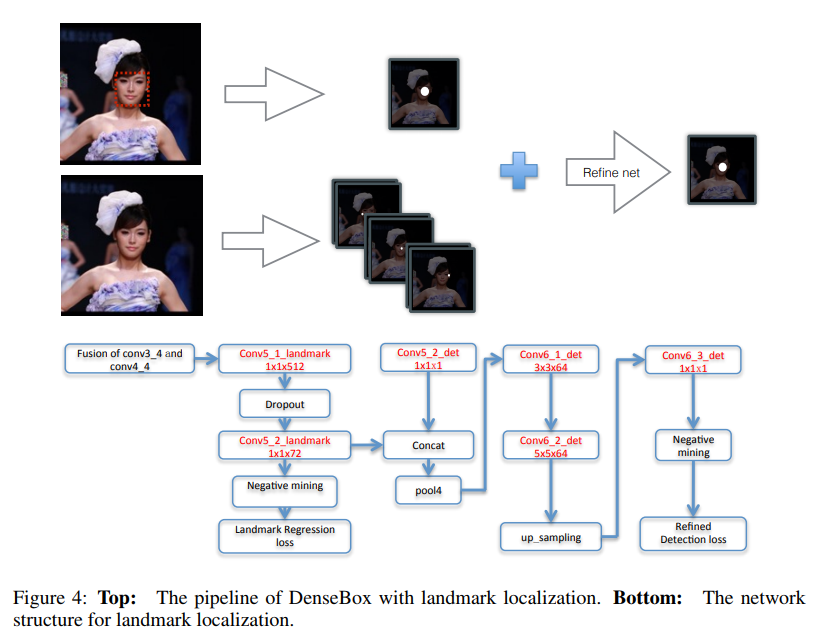
- 这是一篇思路很清晰的文章,看流程图就能明白他做了些什么
- 在那个VGG还盛行的年代,率先使用了高低level通过upsample方式融合特征出结果,还是用了landmark信息refine检测框
- 可惜后续没能深挖下去,不然现有anchor free的结构会提前好些时间出来,可能与 FPN 类似的高低层特征融合 及 ssd 这样多level 出框的思路出来有关
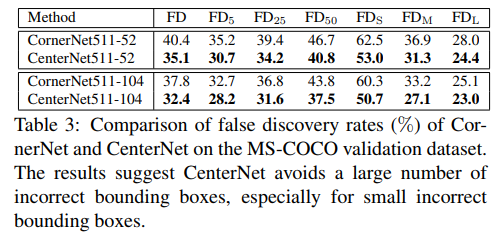
CornerNet
- paper CornerNet: Detecting Objects as Paired Keypoints
- git https://github.com/princeton-vl/CornerNet
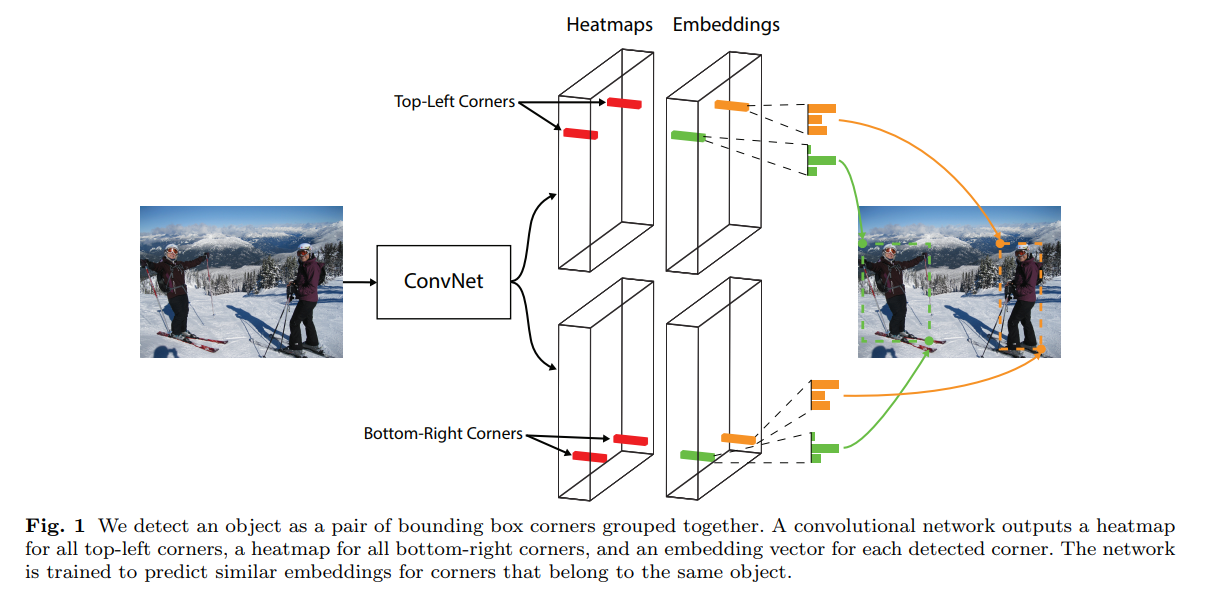
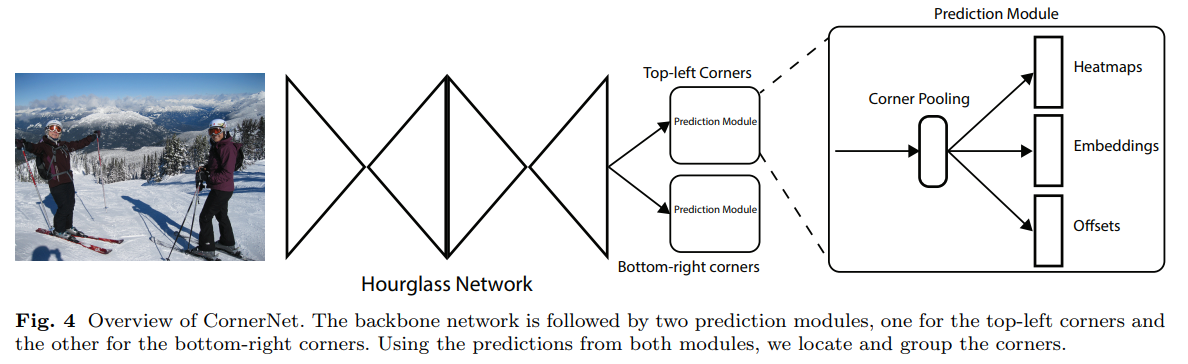
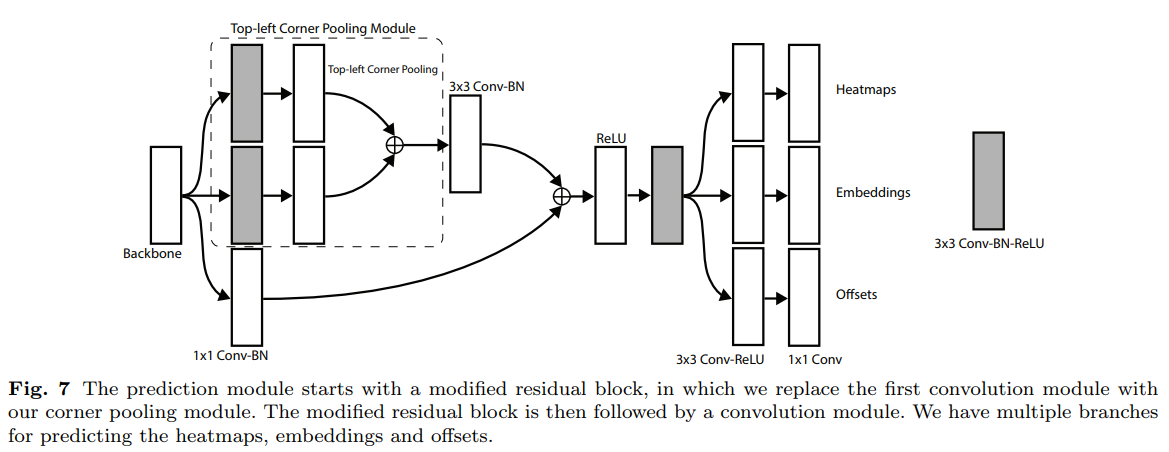
- 这是一篇用人体关键点类似的思路去做检测的文章
- heatmaps: 这个grid是不是要找的 左上|右下 点
- embedings: 向量,用于左上右下点匹配
- offset: 用于关键点微调
- corner pooling: 特殊的maxpooling 用于 进一步凸显 左上|右下 的信息

- 值得一提的文章中类比了两种loss,pull loss用于使CornerPair向量接近更匹配,push loss用于区分不同的CornerPair

- Anchor Free reborn! 原来没有anchor也可以SOTA!
- 文章的创新点太多太多,以至于让人感觉非常的繁复,于是后面的人满脑子想的就是,哎?能不能简单点
- Hourglass-104 太强了!不过真的慢还很大啊
- heatmap 的做法使得 当 classes 很多时计算量很大 又慢了些
- 还得 左上|右下 各算一个heatmap 又慢了些
- 还得匹配 左上|右下 点? 又慢了些
- 还有额外的为了提升这个设计思路的 pooling? 又慢了些
- 总的来说,该文章首次让 anchor free 站上 coco map 40+,researchers 纷纷开始尝试,是不是可以干掉这个该死的anchor
ExtremeNet
- paper Bottom-up Object Detection by Grouping Extreme and Center Points
- git https://github.com/xingyizhou/ExtremeNet

- 看效果牛逼哄哄,究竟是怎么实现的呢?
- We detect four extreme points (top-most, leftmost, bottom-most, right-most) and one center point of objects using a standard keypoint estimation network.
- There are no direct extreme point annotation in the COCO. However, there are complete annotations for object segmentation masks. We thus find extreme points as extrema in the polygonal mask annotations. In cases where an edge is parallel to an axis or within a 3 ◦ angle, we place the extreme point at the center of the edge. Although our training data is derived from the more expensive segmentation annotation, the extreme point data itself is 4× cheaper to collect than the standard bounding box.
- o(╯□╰)o 竟然是从mask里转换出来的,然后还说我这个标注啊比标准的bbox标注便宜4倍 (黑人问号???)
- 文章的启迪来自于 cvpr 2018 的 https://arxiv.org/pdf/1711.09081.pdf Deep Extreme Cut: From Extreme Points to Object Segmentation

- ExtremeNet的主framework, heatmap 对应各个 classification,offset不对类别分别处置,4 x (x,y) x H x w
- 那怎么把这些点组装起来呢


- 第一步,ExtrectPeak。 即提取heatmap中所有的极值点,极值点定义为在3x3滑动窗口中的极大值。
- 第二步,暴力枚举。对于每一种极值点组合(进行适当的剪枝以减小遍历规模),计算它们的中心点,如果center map对应位置上的响应超过预设阈值,则将这一组5个点作为一个备选,该备选组合的score为5个对应点的score平均值。
- 做着做着发现有 ghost box,啥意思呢。
- Center grouping may give a high-confidence falsepositive detection for three equally spaced colinear objects of the same size. The center object has two choices here, commit to the correct small box, or predict a much larger box containing the extreme points of its neighbors. We call these false-positive detections “ghost” boxes.
- 。。。这个不就是你的算法缺陷吗?咋解决呢?
- To discourage ghost boxes, we use a form of soft non-maxima suppression [1]. If the sum of scores of all boxes contained in a certain bounding box exceeds 3 times of the score of itself, we divide its score by 2.
- 堵上。。。真的醉了。
- 然后回归出来的极值点数值不够大,咋整呢?cornernet不是有个corner pooling 使方向上max一致吗,那搞个edge aggregation吧,把极值点加强一下,尽量就一个极值点
- 解决办法是,对每一个极值点,向它的两个方向进行聚集。具体做法是,沿着X/Y轴方向,将第一个单调下降区间内的点的score按一定权重累加到原极值点上。效果如下图所示,可以看出,红圈部分的响应明显增强了。

- 方法太过繁琐,有没有简单方便的方法呢
FSAF
- paper Feature Selective Anchor-Free Module for Single-Shot Object Detection
- Feature Selective Anchor-Free Module for Single-Shot Object Detection 文章title就说明了文章的主体思想,下面两张图也很清晰
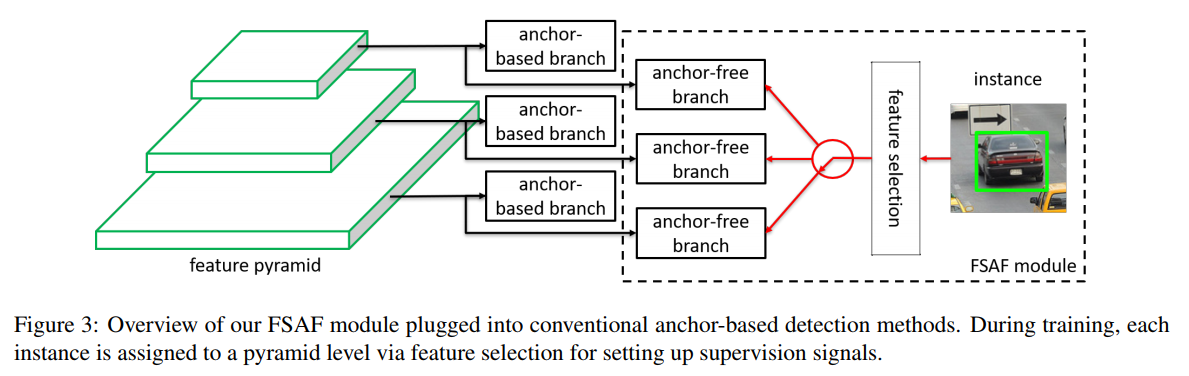
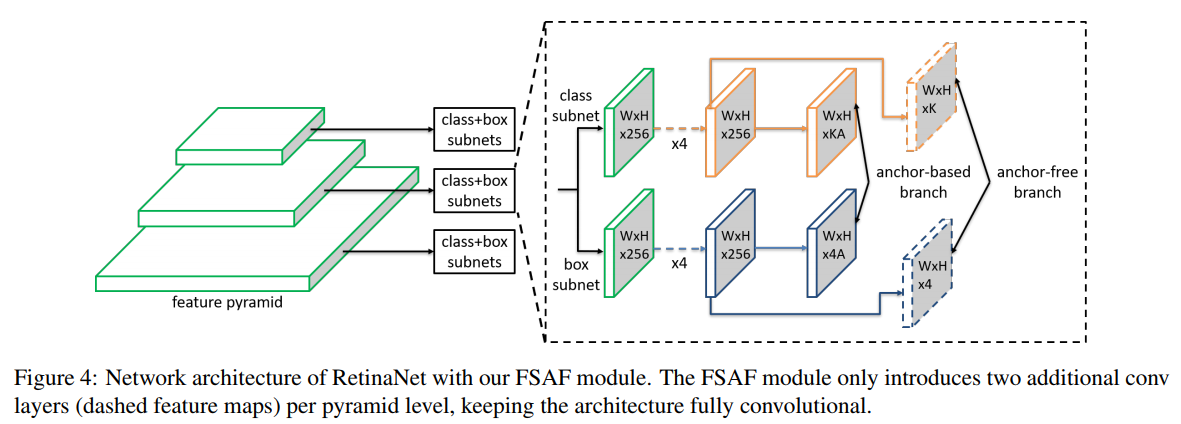
- 主要的motivation是,不同尺寸的物体依据其与FPN每一层 Anchor 的适配程度,分配到不同分辨率的层上进行学习
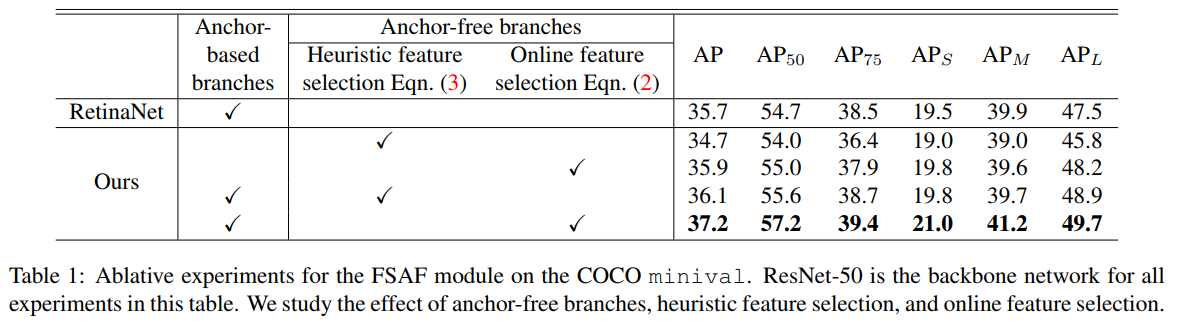
- two limitations:
1) heuristicguided feature selection;
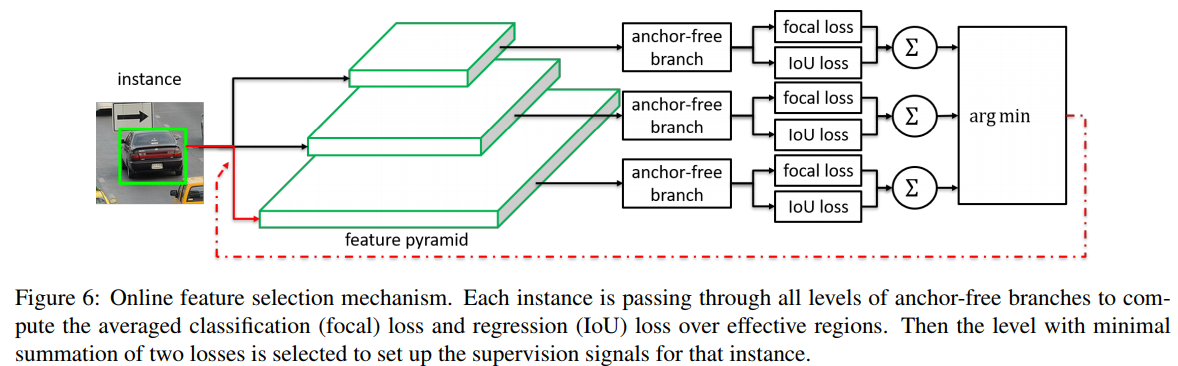
2) overlap-based anchor sampling. During training, each instance is always matched to the closest anchor box(es) according to IoU overlap. And anchor boxes are associated with a certain level of feature map by human-defined rules, such as box size. Therefore, the selected feature level for each instance is purely based on adhoc heuristics. - 这个想法其实是很对的,anchor能iou匹配去搞这些事情,在没有anchor的情况下,我们该如何去分配每一层的目标呢?
- 那就把anchor堆起来,看看那个匹配了形成真值,然后anchor free的分支依据这个真值去选择用那一层的特征去做最后的检测,原文
- Our motivation is to let each instance select the best level of feature freely to optimize the network, so there should be no anchor boxes to constrain the feature selection in our module. Instead, we encode the instances in an anchor-free manner to learn the parameters for classification and regression. The general concept is presented in Figure 3. An anchor-free branch is built per level of feature pyramid, independent to the anchor-based branch. Similar to the anchor-based branch, it consists of a classification subnet and a regression subnet (not shown in figure). An instance can be assigned to arbitrary level of the anchor-free branch. During training, we dynamically select the most suitable level of feature for each instance based on the instance content instead of just the size of instance box. The selected level of feature then learns to detect the assigned instances. At inference, the FSAF module can run independently or jointly with anchorbased branches. Our FSAF module is agnostic to the backbone network and can be applied to single-shot detectors with a structure of feature pyramid. Additionally, the instantiation of anchor-free branches and online feature selection can be various. In this work, we keep the implementation of our FSAF module simple so that its computational cost is marginal compared to the whole network
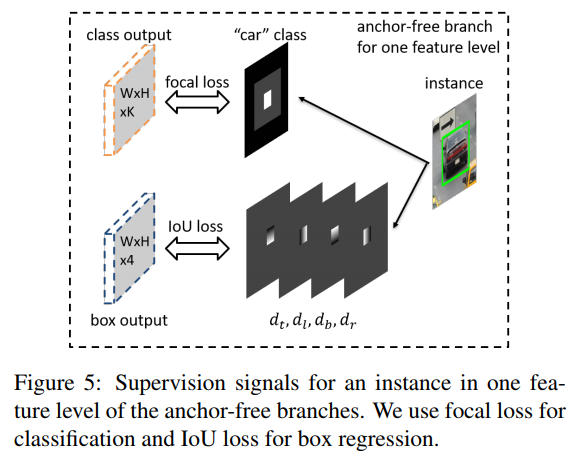
- 那anchor-free的分支是不是在更新参数的时候只更新匹配上的那个level的feature呢? (Online feature selection mechanism)
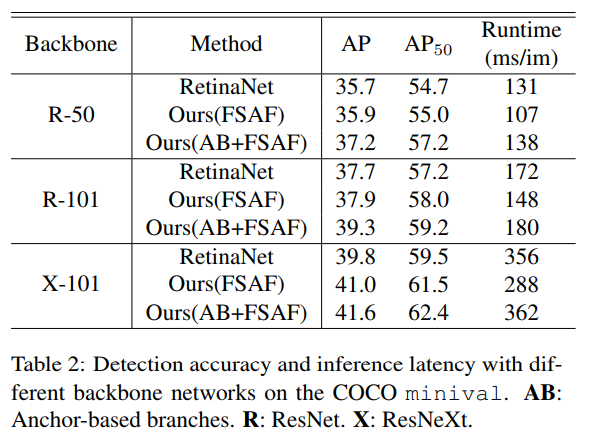
- 关于 inference,作者说anchor-base分支其实在inference的时候是可以不用的,但是不用的话。其实如table2所示,精度上是和原来的retina差不多的
- Inference: The FSAF module just adds a few convolution layers to the fully-convolutional RetinaNet, so the inference is still as simple as forwarding an image through the network. For anchor-free branches, we only decode box predictions from at most 1k top-scoring locations in each pyramid level, after thresholding the confidence scores by 0.05. These top predictions from all levels are merged with the box predictions from anchor-based branches, followed by non-maximum suppression with a threshold of 0.5, yielding the final detections.
- 文章目前没有官方的开源代码,总体来说结论偏向于,训练时候 anchor-base 和 anchor-free 共存,在inference阶段可以单独使用anchor-free分支或者联合使用
- 这是首个在inference阶段的anchor-free能到达anchor-base精度的文章,最最重要的一点是,如何让anchor-free能work well,不同level的feature会成为关键
FCOS
- paper FCOS: Fully Convolutional One-Stage Object Detection
- git https://github.com/tianzhi0549/FCOS

- 文章里有提到一个例子,对于anchor-free而言,对于一个grid,很有可能会作为多个 obj 的center,那如何解决这个问题呢?使用mul-level feature
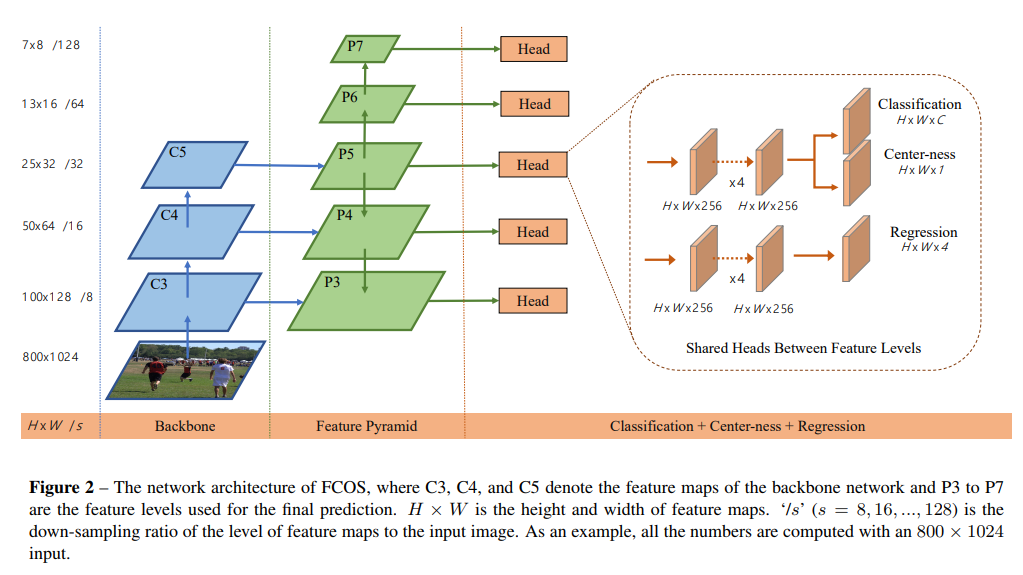
- 蓝色 + 绿色 是标准的 ssd-fpn 的结构,head 里也是常规的 tower, 额外引入了一个center-loss作为辅助
- 那如何在无anchor的情况下去正确匹配ground truth呢?如何解决前言的问题呢?
- 估计是受 FSAF 和 trident RCNN,SNIPER 启发,作者让每一层仅关注对应大小的bbox,让不同 level 的 feature 出 不同大小的 bbox,从而避免了前言里的问题(当然这有一个前提:同样大小的同一类别obj不会拥有同一个center)
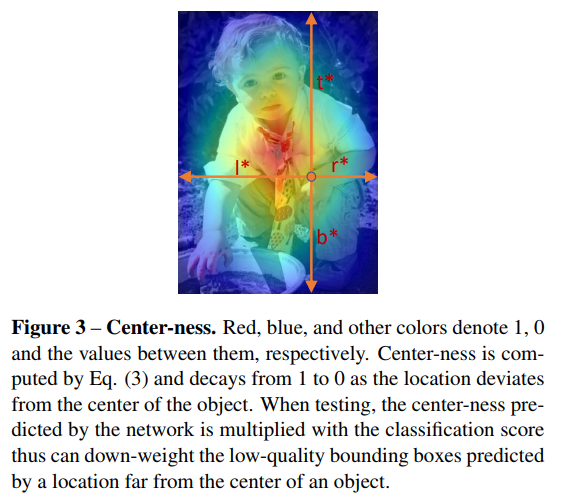

- 这个center-ness的思路是很好的。对于一个ground truth,可能grid不足以完全匹配其center,周边会有好几个近邻的grid都匹配上了。那如何去筛选呢?当然是选最近的。
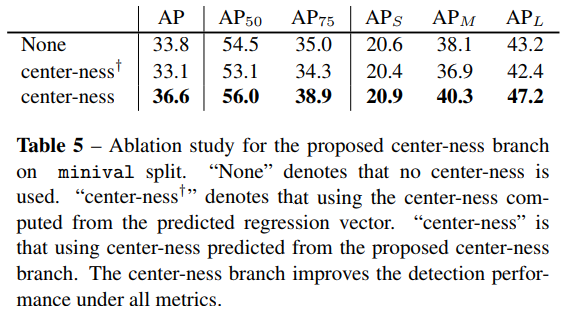
- 作者在插入 center-ness 分支的时候也做了实验,这是一个由中心距算出来的loss是不是应该插在 regression 分支呢? 作者做了实验,发现插 regression 分支还不如不插。
- 我个人的理解是,虽然这是一个和距离相关的loss,但其实仍然是一个分类为目的的loss,用于区分其是否为中心点,与最后分类的分值相辅相成,所以还是加在 分类 的分支里
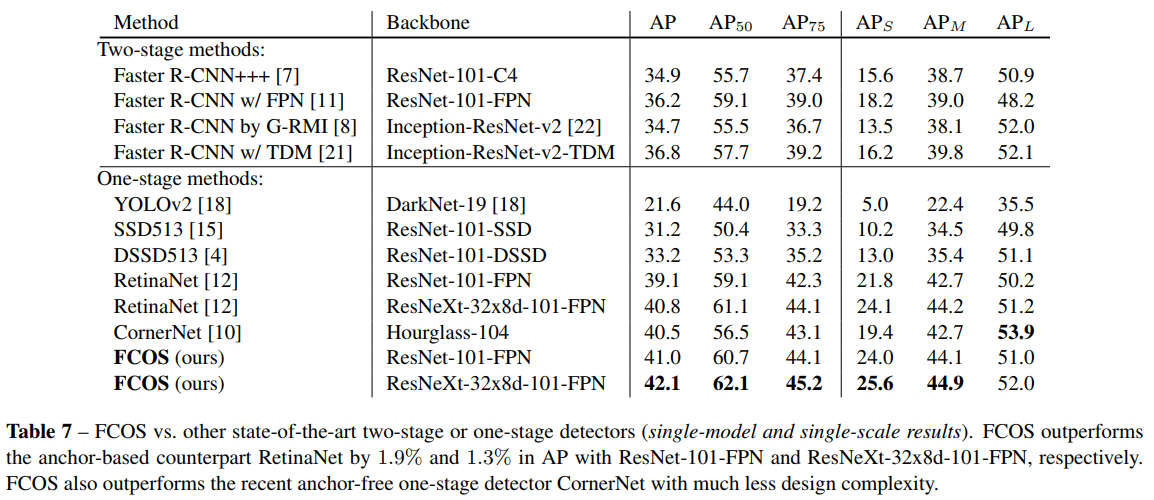
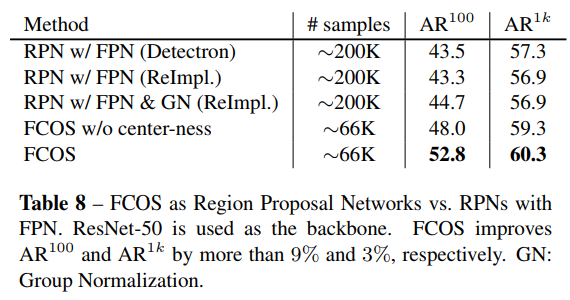
- 最后,作者还就FCOS作为RPN网络进行了分析,实验证明,FCOS不仅recall更高而且在高IOU threshold下效果依然好过retinanet
- 值得推荐的好方法
- 值得一提的是社区给作者提供了许多改进点,速度不变的情况下提升了1.*%的COCO map,具体可以看git repo
CenterNet-op
- paper Objects as Points
- git https://github.com/xingyizhou/CenterNet
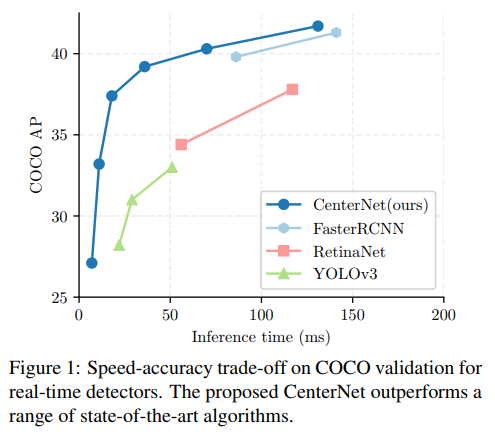
- 上来就是拳打RetinaNet, 脚踢YOLO3
- CenterNet achieves the best speed-accuracy trade-off on the MS COCO dataset, with 28.1% AP at 142 FPS, 37.4% AP at 52 FPS, and 45.1% AP with multi-scale testing at 1.4 FPS.
- 看看他究竟是怎么做的
- 首先假设输入图像为I(W H 3),其中W和H分别为图像的宽和高,然后在预测的时候,我们要产生出关键点的热点图(keypoint heatmap):Y(W/R H/R C)
- 其中R为输出对应原图的步长,而C是在目标检测中对应着检测点的数量,如在COCO目标检测任务中,这个C的值为80,代表当前有80个类别。
- We use the default output stride of R = 4 in literature [4,40,42]. The output stride downsamples the output prediction by a factor R. A prediction Yˆ x,y,c = 1 corresponds to a detected keypoint, while Yˆ x,y,c = 0 is background.



- 说的很明白。
- h = H // 4 w = W // 4
- hw: nchw wh: n2hw reg: n2h*w
- 对于每一个类分别生成heatmap,将gt keypoints以高斯核的形式结合进去形成easy-hard mining类似的heatmap
- 使用 l1 loss 作为regression的loss
- 后处理 对hw使用 sigmoid + maxpooling 进行nms,取代了传统的nms模块,说是很efficient 在我看来也只是对于 anchor很多情况下 nms慢的问题,anchor少的时候优势不大
- 附源代码
1
2
3
4
5
6
7
8
9def _nms(heat, kernel=3):
pad = (kernel - 1) // 2
hmax = nn.functional.max_pool2d(
heat, (kernel, kernel), stride=1, padding=pad)
keep = (hmax == heat).float()
x = heat * keep
return x
hm = output['hm'].sigmoid_()
heat = _nms(heat) 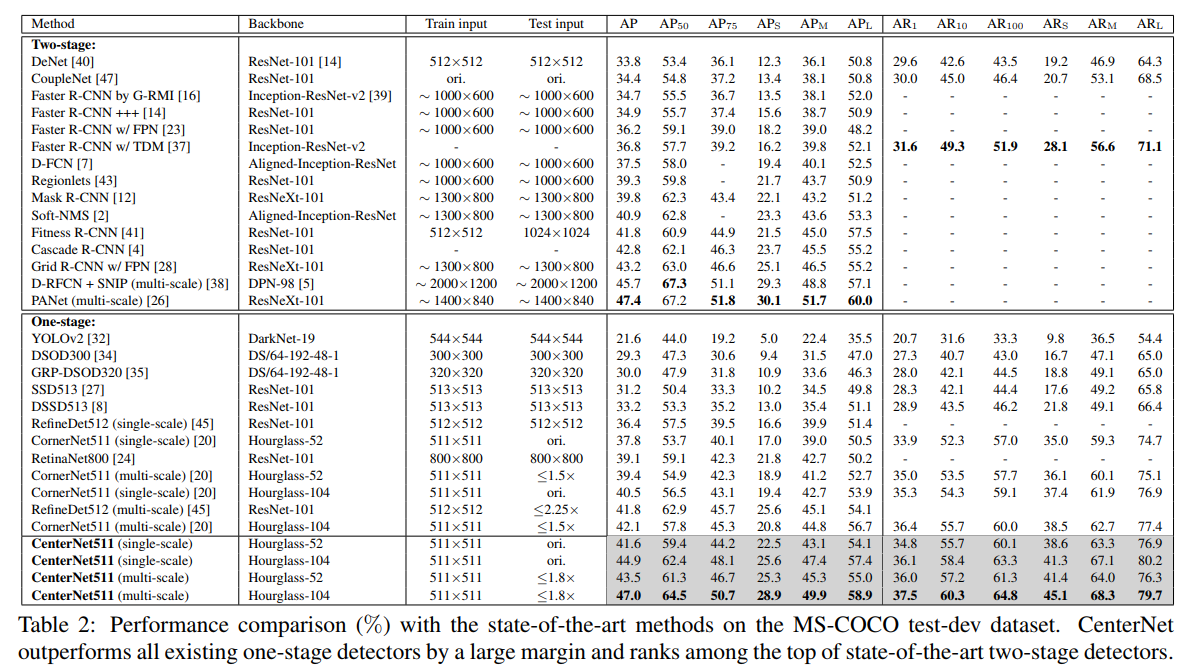
- 同样是简单有效的方案
- 对backbone有很大的依赖,当backbone能力下降时(不适用dcn)效果下降迅速,不适合端化
- 当分辨率提高时计算量增幅大
- 当中心点重合时,由于单grid只回归一个框,故会出现意料之外的问题
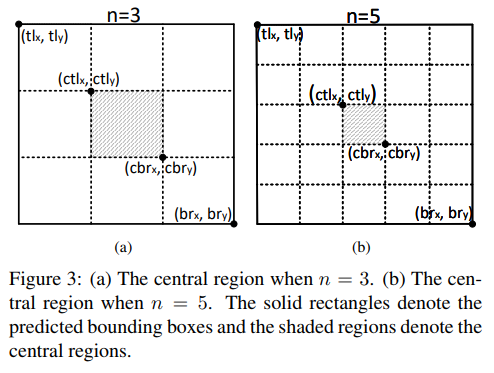
CenterNet-kt
- paper CenterNet: Keypoint Triplets for Object Detection
- git https://github.com/Duankaiwen/CenterNet
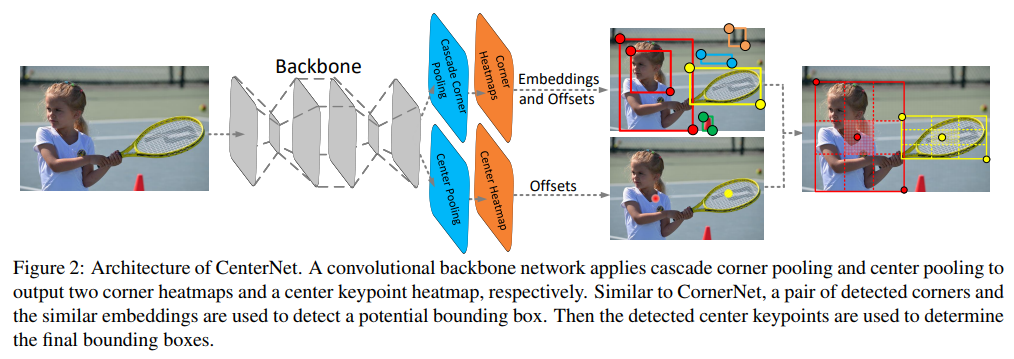
- CornerNet 换个思路版本
- 本文利用关键点三元组即中心点、左上角点和右下角点三个关键点而不是两个点来确定一个目标,使网络花费了很小的代价便具备了感知物体内部信息的能力,从而能有效抑制误检。另外,为了更好的检测中心点和角点,我们分别提出了 center pooling 和 cascade corner pooling 来提取中心点和角点的特征。 啥意思呢?CornerPair对当且仅当其中心位置附近包含Center时才算是真的是个bbox
- 先从特征对齐角度分析一波motivation
- 为啥2阶段好呢?有roi pooling,分类的结果和bbox的信息是对齐的;但凡是anchor-based的one-stage det方案,anchor和特征就是对不齐的,CornerNet虽然没有anchor也有存在这样的问题
- 咋整呢?那我是不是可以验证一下这个框到底对不对
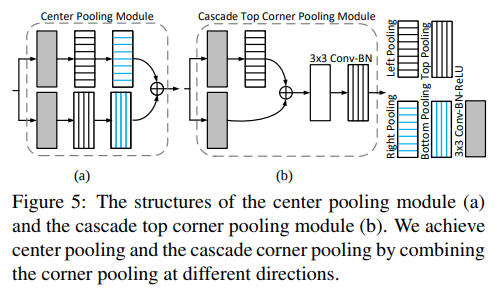
- 作者把自己的方法叫做 Object Detection as Keypoint Triplets
- 通过 center pooling 和 cascade corner pooling 分别得到 center heatmap 和 corner heatmaps,用来预测关键点的位置。得到角点的位置和类别后,通过 offsets 将角点的位置映射到输入图片的对应位置,然后通过 embedings 判断哪两个角点属于同一个物体,以便组成一个检测框。相似于CornerNet的Pooling,本文也有一个CenterPooling
- 其他的就和CornerNet一样了,就不重复叙述了,上结果
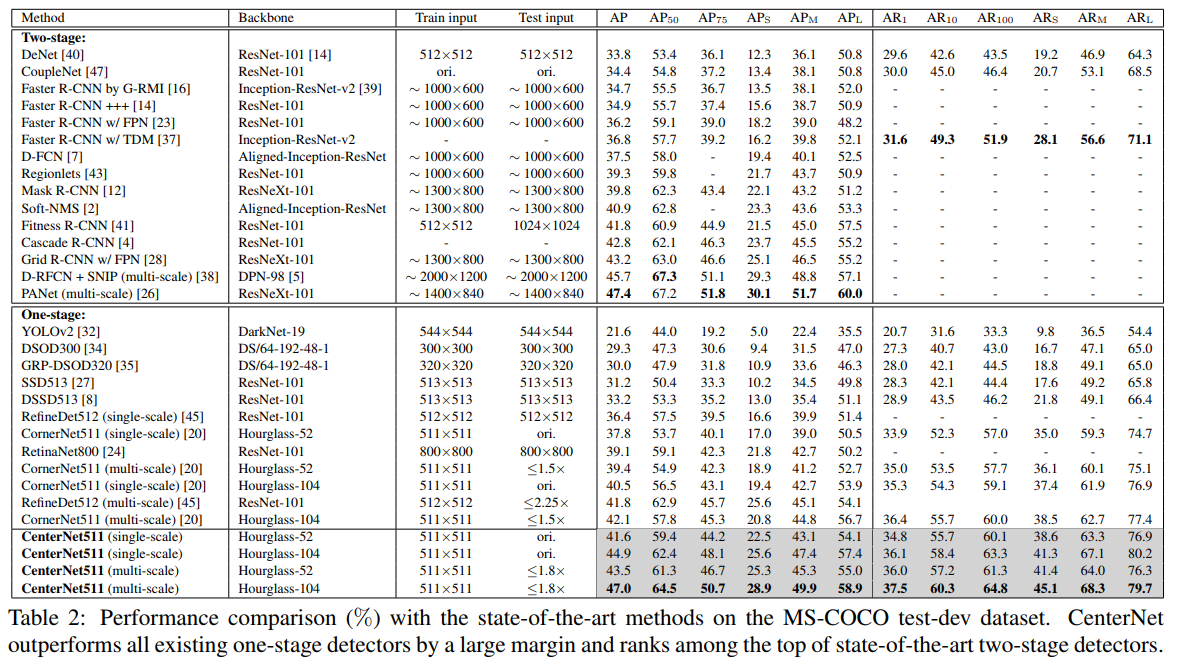
- 结果还是很强势的,吊打了在座的各位 One-Stage Det,但是由于是CornerNet加重版,inference的速度还是有点慢的 (且仅仅511*511 分辨率)
- With an average inference time of 270ms using a 52-layer hourglass backbone [29] and 340ms using a 104-layer hourglass backbone [29] per image, CenterNet is quite efficient yet closely matches the state-of-the-art performance of the other twostage detectors.
- 很强大,相当于CornerNet上再加了一层是否包含Center的判断,就是太慢了
CornerNet-Lite
- paper CornerNet-Lite: Efficient Keypoint Based Object Detection
- git https://github.com/princeton-vl/CornerNet-Lite
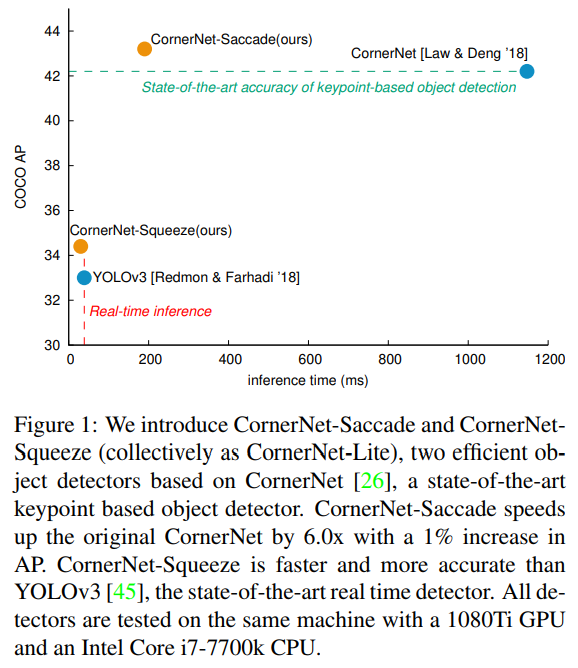
- 上来就是拳打前作cornernet,脚踢正在风头的YOLO3,那么问题来了。这上面的inference time竟然是在7700k+1080ti上的时间。。。(令人害怕)
- 恩,我觉得我们这个conrnet是有点慢啊,那要不减少点计算的像素量不改变结构或者是干脆减轻结构?
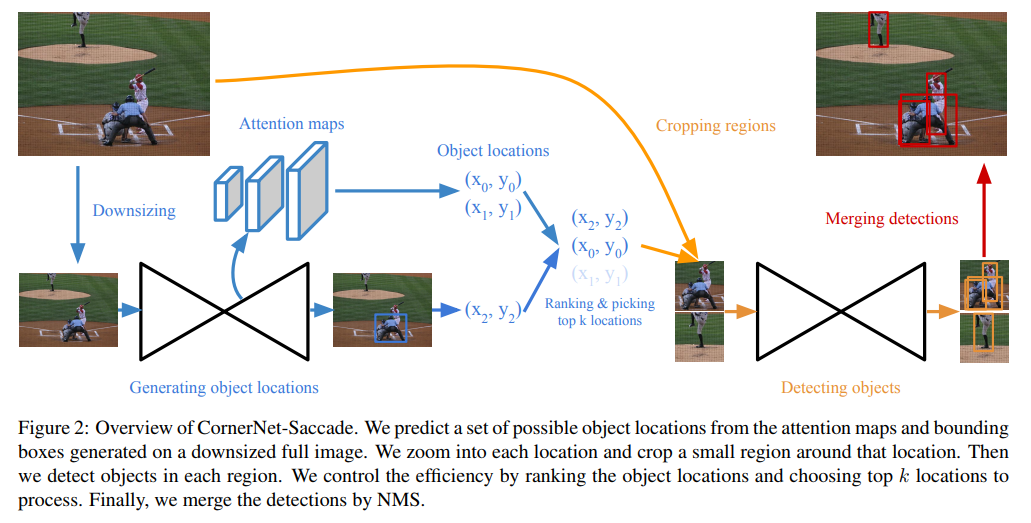
- saccade的overview。全图直接检测好烦,计算量太大了。我先down size,然后生成类似与trident的三个level的attention maps,映射到原图剪出来,然后走正常的cornernet流程。。。
- 值得一提的是。。作者说这样做相较于CornerNet原生减少了6x的时间而且仅提升了1%的accuracy。
- 这一整套的出发点和处理技巧和SPIPER和相似。说实在的。。这个结构说他 two-stage 一点也不冤枉啊。。
- 接下来看 squeeze,核心思路是 well-known 的depth wise conv,和预期的相似,cornernet-squeeze 变快了,精度也下降了

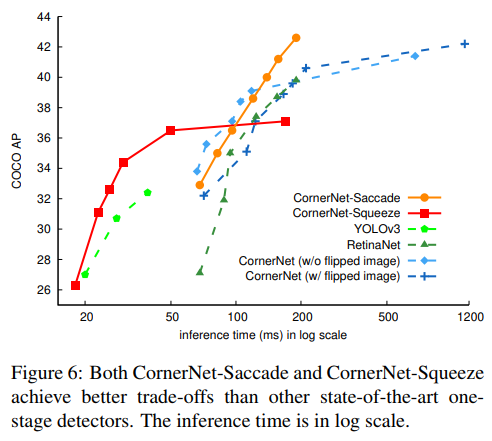
- 最后,作者提出了 cornernet-saccade的几个亮点:1-训练占用内存少2-attention效果拔群3-用了Hourglass-54精度还上升了!
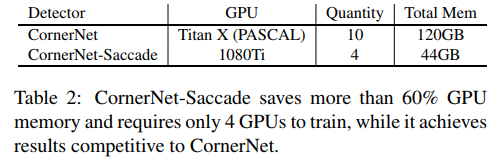
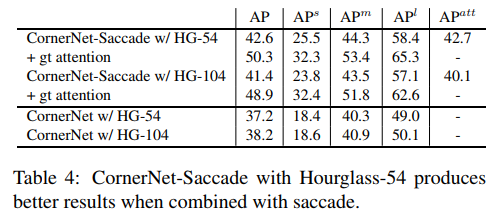
- 实验做的好,说什么都对。不过话说回来,对于尺寸较小的图片,深的网络确实不一定比稍微浅一些的网络强。经过gt-attention裁剪原图后图片基本变小了
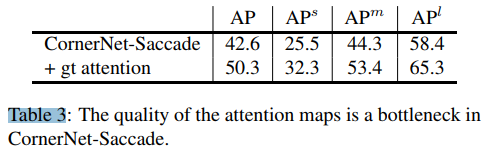
- 值得一提的是,corner-saccade 的 APs 高的吓人,但此处并非coco-test的结果,下面的才是。 24.4也是当前one-stage中 APs 非常高的存在了
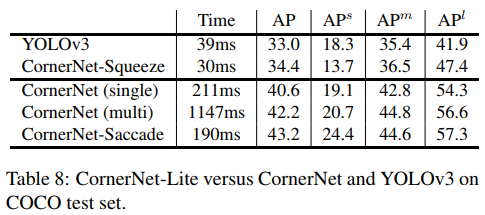
- (伪)one-stage 当前最高精度可能性的存在
RepPoints
- paper RepPoints: Point Set Representation for Object Detection
- git https://github.com/microsoft/RepPoints
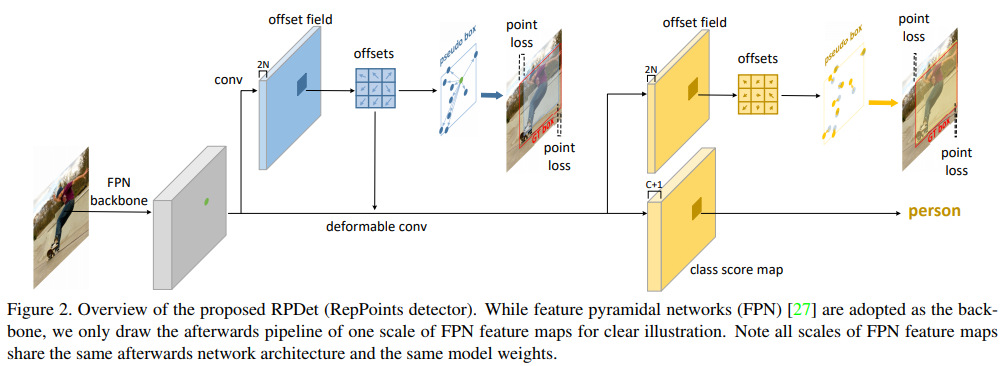
- 干净利落的 refineDet 加强版?
- any FPN branch feature – 1st deconv (point loss 1) – 2st deconv (point loss 2) + normal class pred
- 这个deconv怎么用来算bbox呢


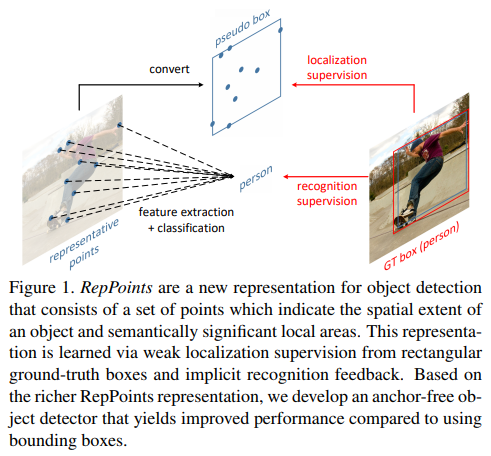
- 使用 1st DCONV 的 OFFSET_MAP 作为回归的 pseudo BOX(生成‘anchor’),然后对其进行分类,微调
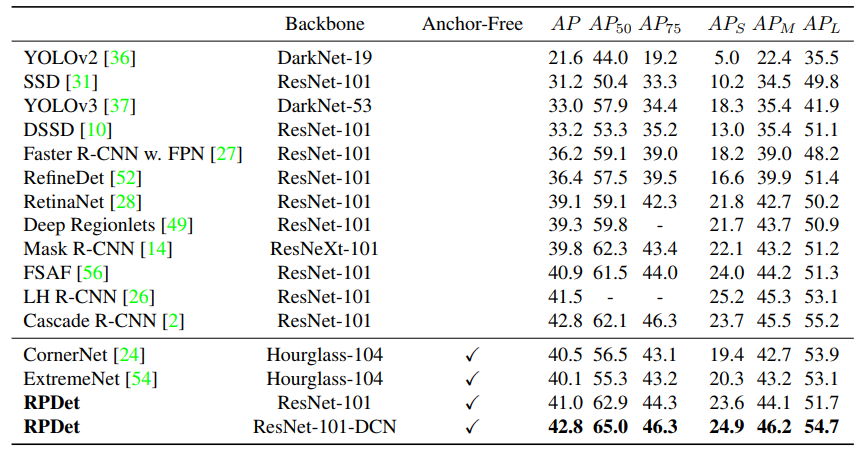
- 文章思路新颖,颇有开辟新流派的趋势