梳理 Pedestrian Detection(行人检测) 相关介绍,数据集,算法
Intro
Foreword
- 和通用检测不同,行人检测顾名思义,是只有行人一类的,特殊的前景类检测,其难点在于:
- occlusion
- 行人检测往往是安防视角或者自动驾驶视角,行人的完整度往往难以保证,容易被遮挡
- crowd
- 现有方法的detection往往伴随着nms,在过于密集的场景下,紧挨着的行人往往容易被过滤掉
- occlusion
- 本文档着重于介绍行人检测专用数据集,算法,及与常规检测方法的对比实验
Algorithm
此处的讨论仅限于在 caltech or cityperson 上做过实验的文章
MS-CNN
- paper A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection
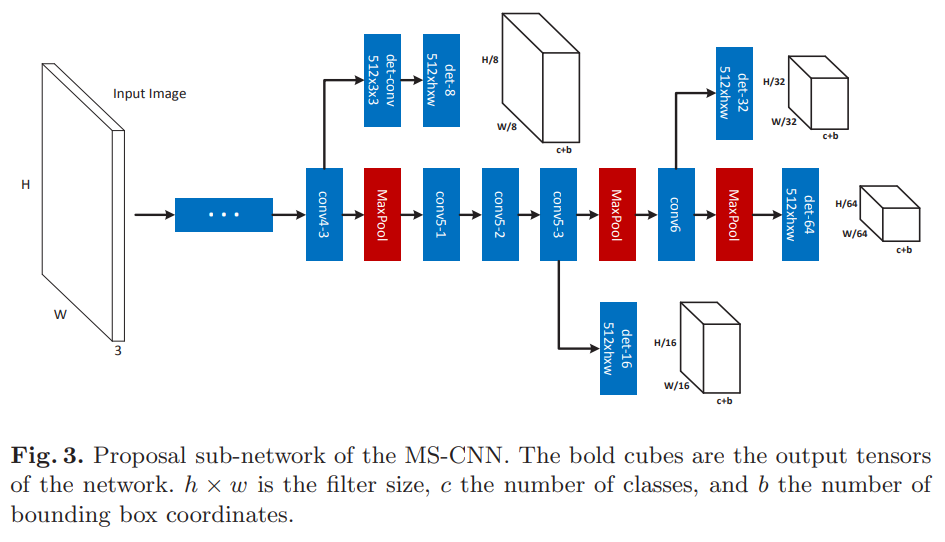
- 全文只要思想就是解决目标scale变化的问题,在16年时这样的想法还比较先进,初始化了cityperson baseline 13.32%
Repultion Loss
- paper Mask-Guided Attention Network for Occluded Pedestrian Detection
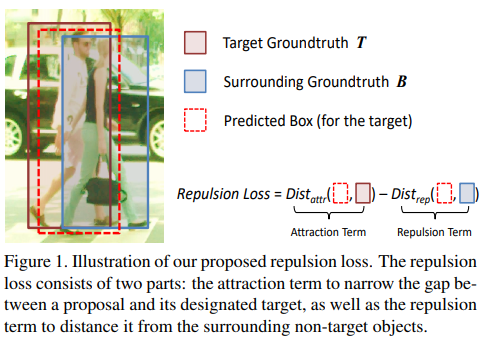
- 主要思想就是解决一个预测框在两个框中间重叠的情况,也就是所谓的crowd的情况
OR-CNN
- paper Occlusion-aware R-CNN: Detecting Pedestrians in a Crowd
- main contribution
- We propose a new occlusion-aware R-CNN method, which uses a new designed AggLoss to enforce proposals to be close to the corresponding objects, as well as minimize the internal region distances of proposals associated with the same objects.
- 我们提出了一种新的关注遮挡的RCNN,使用了全新的AggLoss
- We design a new PORoI pooling unit to replace the RoI pooling layer in the second Fast R-CNN module to integrate the prior structure information of human body with visibility prediction into the network.
- 我们设计了一种新的POROI pooling取代了原先的ROI pooling
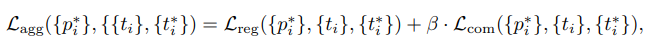
- agg loss加在rpn上,是由 smooth-L1 和 compactness loss 组成
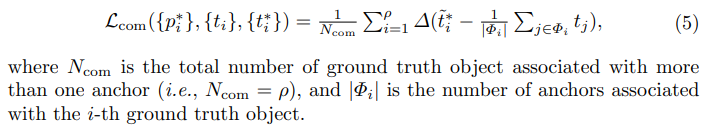
- com loss 主要用来约束能匹配gt的anchor refine后能尽可能紧致(框的均值离真值小)
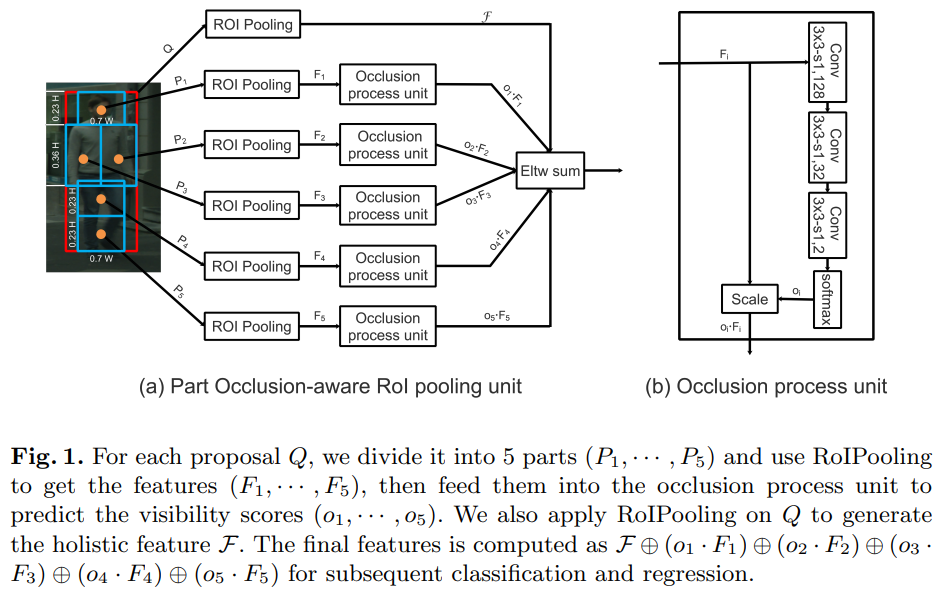
- OROI pooling
- 对一个proposal Q,我们将其分为5部分,使用roi pooling得到这五个部分的特征,然后将其喂入OP unit
- op unit主要就是一个前后景的attention
- 最后elewise sum

- cityperson 有可见区域的标签,将5个部分于课件区域IOU进行计算,得到 occlusion loss
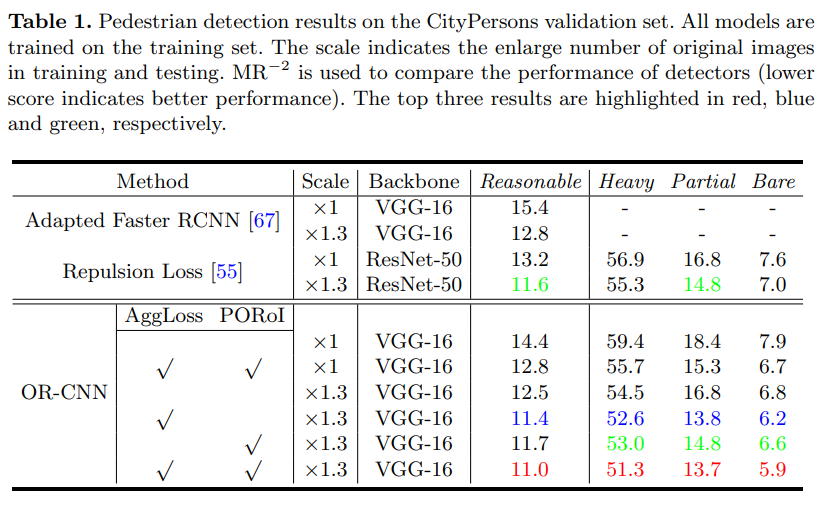
- 1.3X的VGG16对应val集的 R 11 H 51.3 是非常强的结果了,也是之后工作经常拿ORCNN作为baseline的原因之一
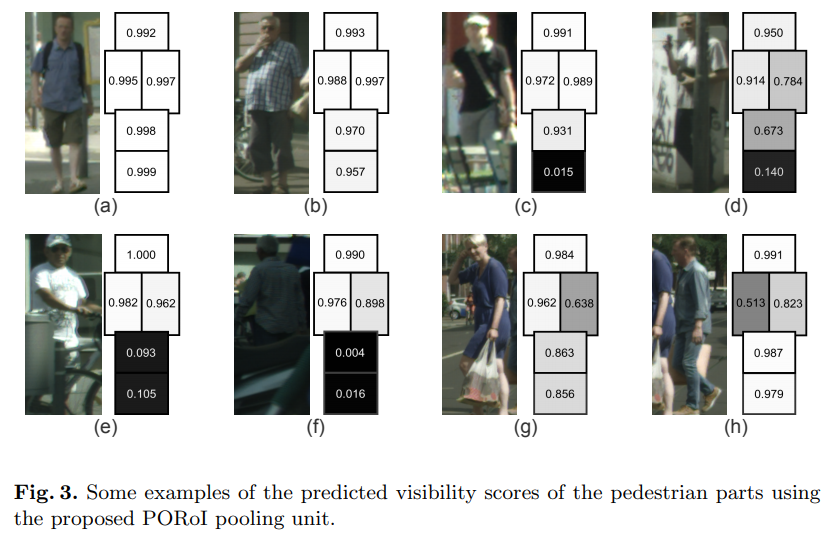
- POROI pooling结果示意图,理想状态下,被遮挡的部位分值低,但不影响其他部分分值
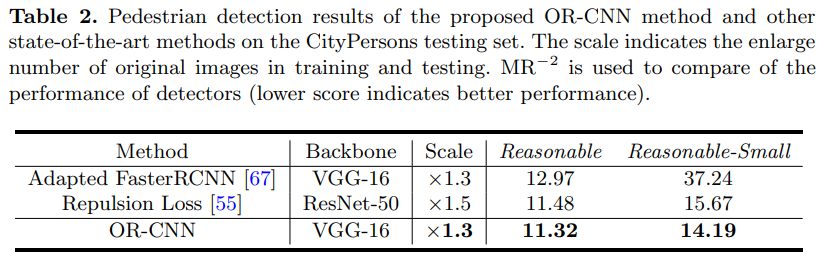
- 在test集上表现为 R 11.32,非常不错的成绩
CSP
- paper Center and Scale Prediction: A Box-free Approach for Object Detection
- git https://github.com/liuwei16/CSP
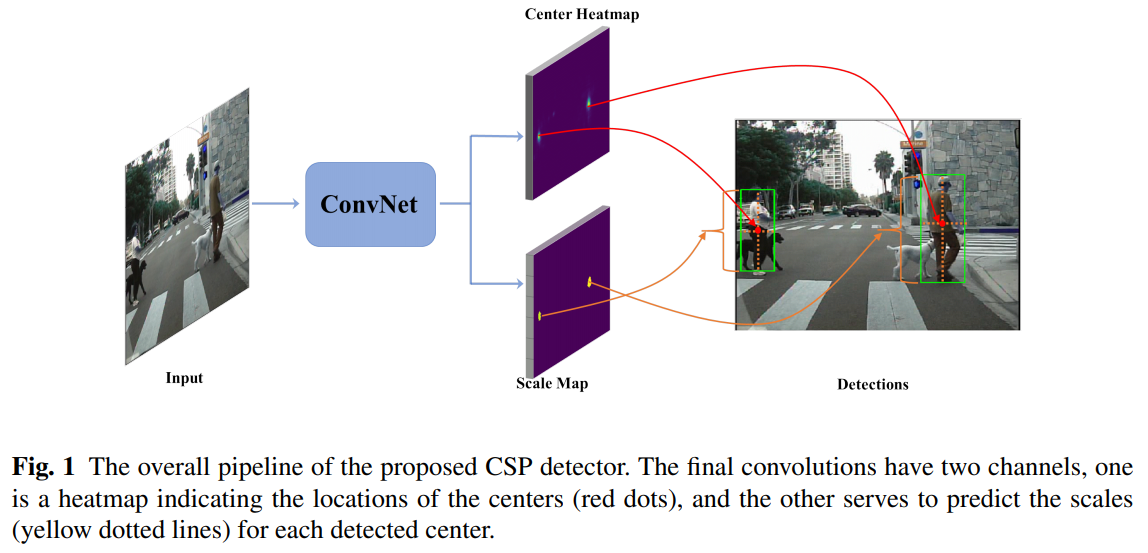
- convNet的整体框架图,和anchor free的算法们惊人相似,出的时间也相似,都是受CornerNet启发
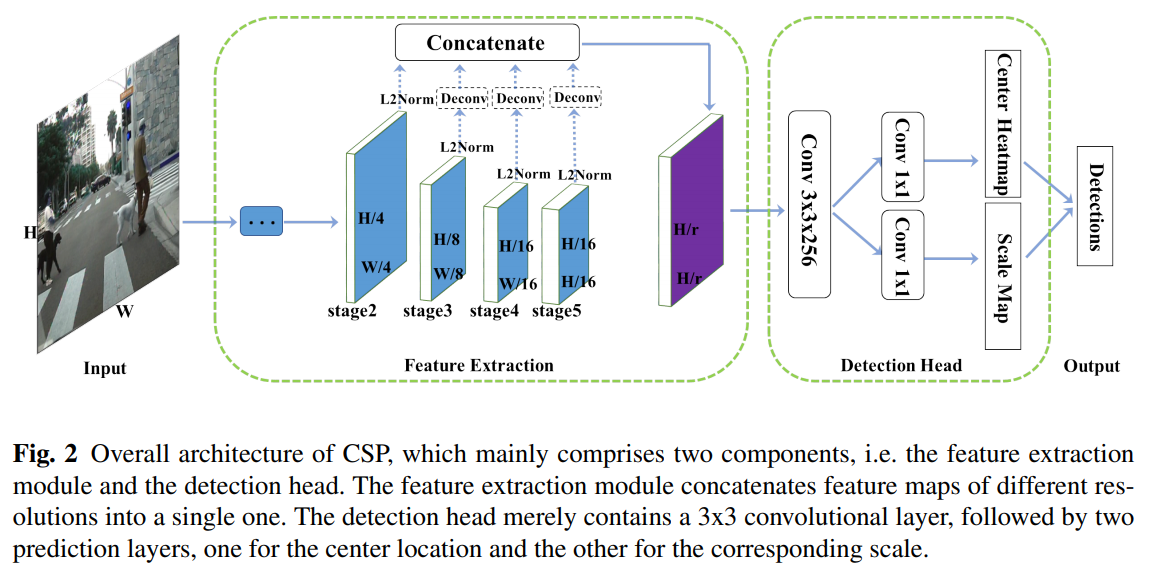
- 具体框架图,concat mul-level feature,整体conv出heatmap和scale map,和centernet如出一辙

- ussion mask 来做heatmap,也是关键点任务中常见的转换
- Scale can be defined as the height and/or width of objects. Towards high-quality ground truth for pedestrian detection, line annotation is first proposed in [54, 55], where tight bounding boxes are automatically generated with a uniform aspect ratio of 0.41.
- 相当于是固定了anchor ratio去预测scale。由于pedestrian往往是站立的人,长宽比被预设为0.41
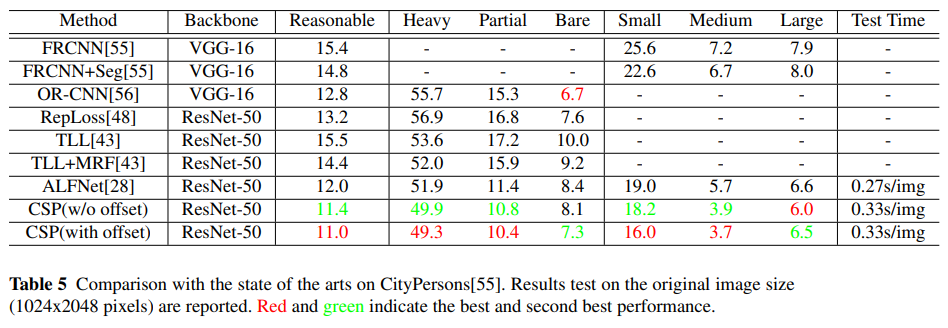
- 在1x上跑出了OC RCNN 1.3x的结果,非常的不错
- 作者顺路还在widerface上测试了下,效果还不错
- CSP其实和常规的检测算法没有太大区别了
MGAN
- paper Mask-Guided Attention Network for Occluded Pedestrian Detection
- git https://github.com/Leotju/MGAN

- 相较于baseline,MGAN能检测出更多的pedestrian
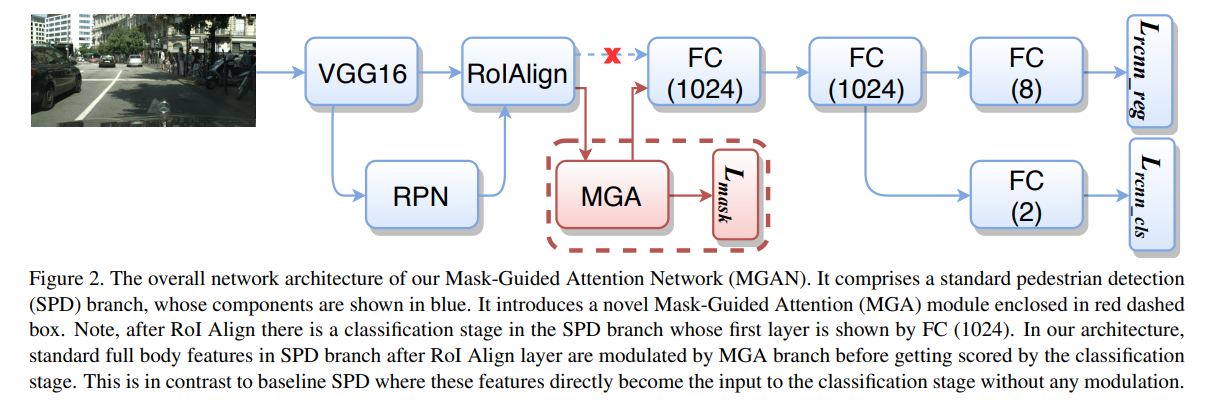
- 相较于FRRCNN,仅新增了MGA模块
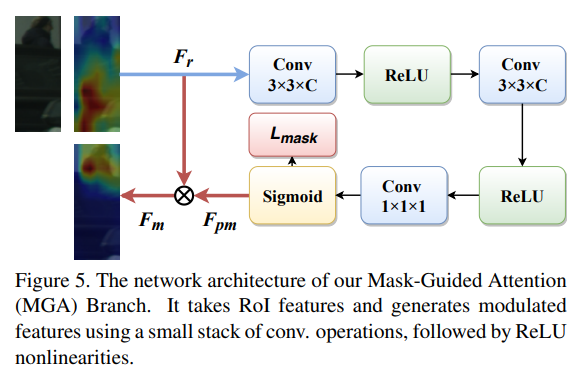
- MGA模块详解,主要作用是生成attention mask重权重feature map
- We therefore adapt visible-region bounding box annotation as an approximate alternative.
- 使用visible region生成粗粒度的mask用于监督attention
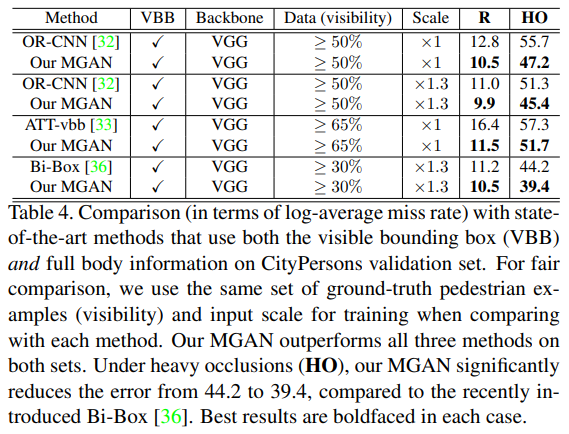
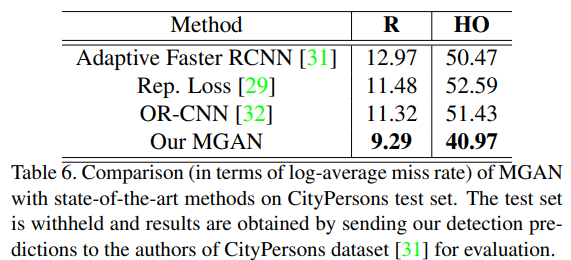
- 相较于其他算法,MGAN的干净简单的做法赢得了更好的R与HO
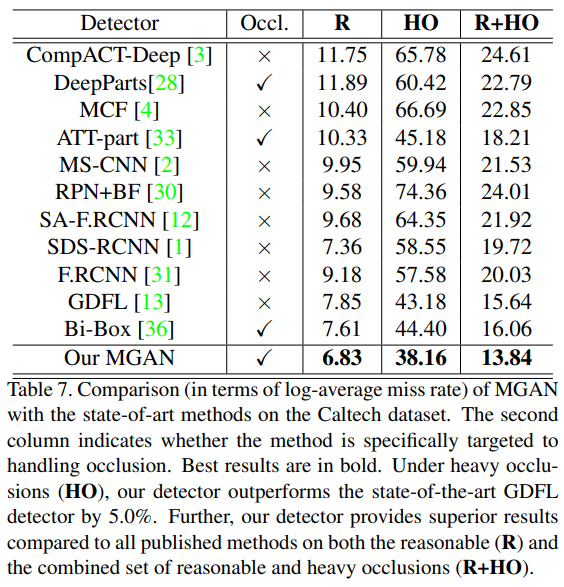
- 在caltech上效果也非常好
- 这里不得不提这个Bi-Box
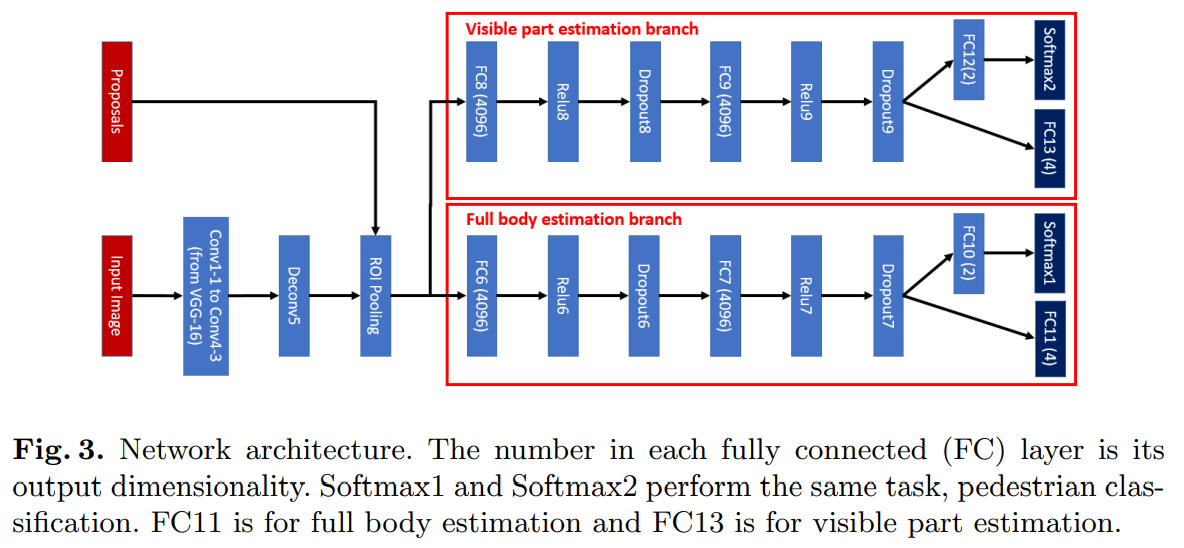
- 也是希望通过利用visible part的信息,改善recall,但是bi-box是两个分支,没有相互间的特征融合,而且对于行人对象,将可视部分视为全身的一部分(前置)而非另一个类,是一个更好的选择
dataset
一般来说,CityPersons数据集较小也有代表性,适合实验
CityPersons
- a benchmark for CityPersons, which is a subset of the Cityscapes dataset.
- 项目库 https://bitbucket.org/shanshanzhang/citypersons/src/default/
- Benchmark
| Method | MR (Reasonable) | MR (Reasonable_small) | MR (Reasonable_occ=heavy) | MR (All) |
|---|---|---|---|---|
| APD* | 8.27% | 11.03% | 35.45% | 35.65% |
| YT-PedDet* | 8.41% | 10.60% | 37.88% | 37.22% |
| STNet* | 8.92% | 11.13% | 34.31% | 29.54% |
| MGAN | 9.29% | 11.38% | 40.97% | 38.86% |
| DVRNet* | 10.99% | 15.68% | 43.77% | 41.48% |
| HBA-RCNN* | 11.26% | 15.68% | 39.54% | 38.77% |
| OR-CNN | 11.32% | 14.19% | 51.43% | 40.19% |
| Repultion Loss | 11.48% | 15.67% | 52.59% | 39.17% |
| Cascade MS-CNN | 11.62% | 13.64% | 47.14% | 37.63% |
| Adapted FasterRCNN | 12.97% | 37.24% | 50.47% | 43.86% |
| MS-CNN | 13.32% | 15.86% | 51.88% | 39.94% |
Caltech
- home http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
- The Caltech Pedestrian Dataset consists of approximately 10 hours of 640x480 30Hz video taken from a vehicle driving through regular traffic in an urban environment. About 250,000 frames (in 137 approximately minute long segments) with a total of 350,000 bounding boxes and 2300 unique pedestrians were annotated. The annotation includes temporal correspondence between bounding boxes and detailed occlusion labels. More information can be found in our PAMI 2012 and CVPR 2009 benchmarking papers.

- 没错,就是fb三剑(ji)客(lao)之一的 Piotr Dollár 主导的项目。coco他也是主导者之一
crowd human
- home http://www.crowdhuman.org/
- face ++ 出品
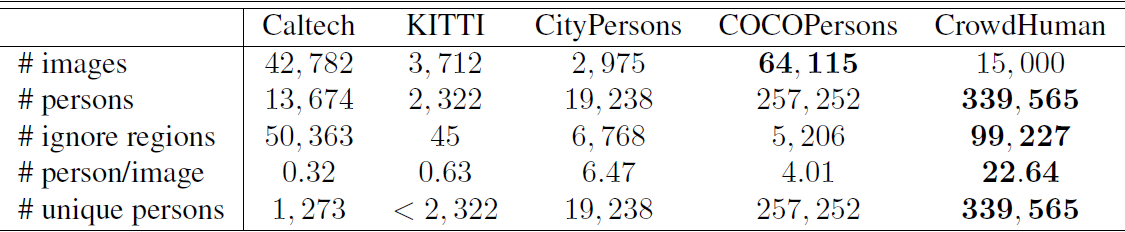
- 这是一个新的数据集,相较之前的数据集,单图人数更多,不同的person更多,也更加密集

- 在标注上,crowd human也是独具特色
- 有人头和全身的标注
- 有实框(明显的未被遮挡的对象)和虚框(有明显遮挡的对象)的区别
- X 代表ignore