梳理 Crowd Counting(人群密度估计) 相关介绍,数据集,算法
Intro
Foreword
- (mainly forked from https://github.com/CommissarMa/Crowd_counting_from_scratch)
- Crowd counting has a long research history. About twenty years ago or even earlier, researchers have been interested in developing the method to count the number of pedestrians in the image automatically.
- There are mainly three categories of methods to count pedestrians in crowd.
- Pedestrian detector. You can use traditional HOG-based detector or deeplearning-based detector like YOLOs or RCNNs. But effect of this category of methods are seriously affected by occlusion in crowd scenes. (检测器作为拥挤场景下人数估计受遮挡影响巨大)
- Number regression. This category of methods just capture some features from original images and use machine-learning models to map the relation between features and numbers. An improved version via deep-learning directly map the relation between original image and its numbers. Before deep-learning, regression-based methods were SOTA and researchers are focus on finding more effective features to estimate more accuracy results. But when deep-learning get popular and achieve better results, regression-based methods get less attention because it is hard to capture effective hand-crafted features. (使用手工特征 + ml方法进行人数统计,在deep learning之前是最work的方法)
- Density-map. This category of methods are the mainstream methods in crowd counting nowadays. Compared with detector-based methods and regression-based methods, density-map can not only give the information of pedestrian numbers, but also can reflect the distribution of pedestrians, which can make the models to fit original images with opposite density better.(将人群估计转化为 密度图|热力图 的逐像素回归问题是当下最常见的方案)
What is density-map?
- Simply speaking, we use a gaussian kernel to simulate a head in corresponding position of the original image. After do this action for all heads in the image, we then perform normalization in matrix which is composed by all these gaussian kernels. The sample picture is as follows:(密集人群统计的标注都是json化的点,通过映射回原图进行高斯滤波得到gt的热力图)
- Further, there are three strategies to generate density-map.
- use the same gaussian kernel to simulate all heads. This method applies to scene without severe perspective distortion. [fixed_kernel_code]
- use the perspective map(which is generated by linear regression of pedestrians’ height) to generate gaussian kernels with different sizes to different heads. This method applies to fixed scene. [perspective_kernel_code] And [paper-zhang-CVPR2015] give detailed instruction about how to generate perspective density-map.
- use the k-nearest heads to generate gaussian kernels with different sizes to different heads. This method applies to very crowded scenes. [k_nearset_kernel_code] And [paper-MCNN-CVPR2016] give detailed instruction about how to generate k-nearest density-map.
- (具体来说就是 1:形变较小的远距离安防场景用一样尺寸大小的高斯核就行了 2:有形变的就用随着高度变化的高斯核 3:如果说极度密集的话最好使用k近邻方法生成不同尺寸的高斯核)

Model for beginner
- For beginner, [paper-MCNN-CVPR2016] is the most suitable model to learn crowd counting. The model is not complex and have an acceptable accuracy. We provide an easy [MCNN_model_code] to let you know MCNN rapidly and an easy full realization of [MCNN-pytorch]. (MCNN作为人群估计最为经典文章之一,非常适合作为入门首选)
Algorithm
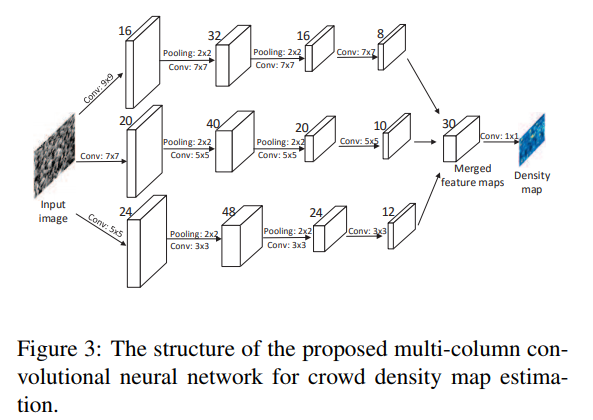
MCNN
- paper Single-Image Crowd Counting via Multi-Column Convolutional Neural Network
- Contributions of this paper
- In this paper, we aim to conduct accurate crowd counting from an arbitrary still image, with an arbitrary camera perspective and crowd density. At first sight this seems to be a rather daunting task, since we obviously need to conquer series of challenges:
- Foreground segmentation is indispensable in most existing work. However foreground segmentation is a challenging task all by itself and inaccurate segmentation will have irreversible bad effect on the final count. In our task, the viewpoint of an image can be arbitrary. Without information about scene geometry or motion, it is almost impossible to segment the crowd from its background accurately. Hence, we have to estimate the number of crowd without segmenting the foreground first. (抠出前景不是必须的了)
- The density and distribution of crowd vary significantly in our task (or datasets) and typically there are tremendous occlusions for most people in each image. Hence traditional detection-based methods do not work well on such images and situations.(热力图特好使)
- As there might be significant variation in the scale of the people in the images, we need to utilize features at different scales all together in order to accurately estimate crowd counts for different images. Since we do not have tracked features and it is difficult to handcraft features for all different scales, we have to resort to methods that can automatically learn effective features.(deep learning来啦小老弟)
- In this paper, we aim to conduct accurate crowd counting from an arbitrary still image, with an arbitrary camera perspective and crowd density. At first sight this seems to be a rather daunting task, since we obviously need to conquer series of challenges:
- To overcome above challenges, in this work, we propose a novel framework based on convolutional neural network (CNN) [9, 16] for crowd counting in an arbitrary still image. More specifically, we propose a multi-column convolutional neural network (MCNN) inspired by the work of [8], which has proposed multi-column deep neural networks for image classification. In their model, an arbitrary number of columns can be trained on inputs preprocessed in different ways. Then final predictions are obtained by averaging individual predictions of all deep neural networks. Our MCNN contains three columns of convolutional neural networks whose filters have different sizes. Input of the MCNN is the image, and its output is a crowd density map whose integral gives the overall crowd count. Contributions of this paper are summarized as follows:
- The reason for us to adopt a multi-column architecture here is rather natural: the three columns correspond to filters with receptive fields of different sizes (large, medium, small) so that the features learned by each column CNN is adaptive to (hence the overall network is robust to) large variation in people/head size due to perspective effect or across different image resolutions.(多分辨率玩法)
- In our MCNN, we replace the fully connected layer with a convolution layer whose filter size is 1 × 1. Therefore the input image of our model can be of arbitrary size to avoid distortion. The immediate output of the network is an estimate of the density.(全卷积替代FC)
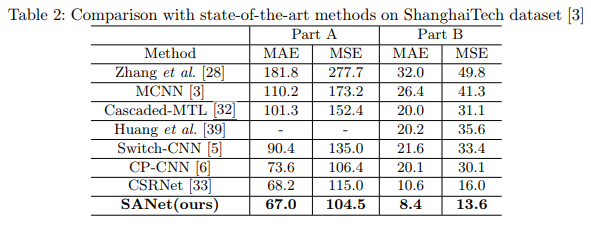
- We collect a new dataset for evaluation of crowd counting methods. Existing crowd counting datasets cannot fully test the performance of an algorithm in the diverse scenarios considered by this work because their limitations in the variation in viewpoints (UCSD, WorldExpo’10), crowd counts (UCSD), the scale of dataset (UCSD, UCF CC 50), or the variety of scenes (UCF CC 50). In this work we introduce a new large-scale crowd dataset named Shanghaitech of nearly 1,200 images with around 330,000 accurately labeled heads. As far as we know, it is the largest crowd counting dataset in terms of number annotated heads. No two images in this dataset are taken from the same viewpoint. This dataset consists of two parts: Part A and Part B. Images in Part A are randomly crawled from the Internet, most of them have a large number of people. Part B are taken from busy streets of metropolitan areas in Shanghai. We have manually annotated both parts of images and will share this dataset by request. Figure 1 shows some representative samples of this dataset.(发布了shanghaitech dataset)
- Density map via geometry-adaptive kernels
- For each head xi in a given image, we denote the distances to its k nearest neighbors as {d i 1 , di 2 , . . . , di m}. The average distance is therefore ¯d i = 1 m ∑m j=1 d i j . Thus, the pixel associated with xi corresponds to an area on the ground in the scene roughly of a radius proportional to ¯d i . Therefore, to estimate the crowd density around the pixel xi , we need to convolve δ(x − xi) with a Gaussian kernel with variance σi proportional to ¯d i .More precisely, the density F should be
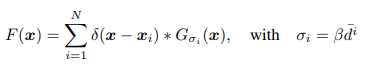
- for some parameter β. In other words, we convolve the labels H with density kernels adaptive to the local geometry around each data point, referred to as geometry-adaptive kernels. In our experiment, we have found empirically β = 0.3 gives the best result. In Figure 2, we have shown so-obtained density maps of two exemplar images in our dataset.

- 启发性里程碑意义的工作,标志着Crowd Counting进入深度时代。从这以后的工作基本就离不开热力图和shanghaitech数据集,基本就是在这篇工作的基础上改进model,大框架基本定性
Cascaded-MTL
- paper CNN-based Cascaded Multi-task Learning of High-level Prior and Density Estimation for Crowd Counting
- git https://github.com/svishwa/crowdcount-cascaded-mtl
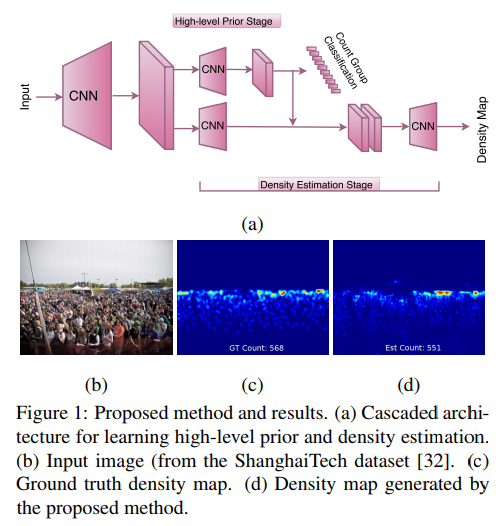
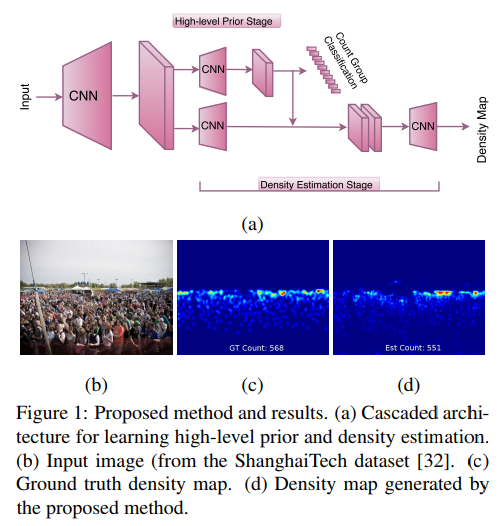
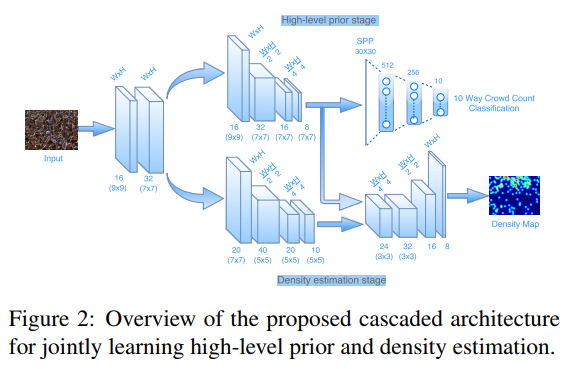
- Proposed method
- Shared convolutional layers
- High-level prior stage
- Classifying the crowd into several groups is an easier problem as compared to directly performing classification or regression for the whole count range which requires a larger amount of training data. Hence, we quantize the crowd count into ten groups and learn a crowd count group classifier which also performs the task of incorporating high-level prior into the network. Cross-entropy error is used as the loss layer for this stage. (将人群计数任务映射成为10类拥挤程度的分类问题)
- Density estimation
- Standard pixel-wise Euclidean loss is used as the loss layer for this stage. Note that this loss depends on intermediate output of the earlier cascade, thereby enforcing a causal relationship between count classification and density estimation.
- Objective function
- Experiment
- 这是第一篇提出将分类计数和热力图联合训练提高效果的文章,相较MCNN提升比较明显。后面几年没有人在这个方向继续深挖,直到19年出现一个人用类似思路在part B的MAE刷到了7以内,那就是后话了

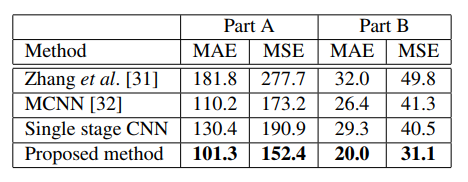
CSRNet
- paper CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes
- https://github.com/leeyeehoo/CSRNet-pytorch
- Proposed Solution
- CSRNet architecture
- Dilated convolution
- Network Configuration
- Dilated convolution
- Training method
- Ground truth generation
- follow mcnn
- Data augmentation
- We crop 9 patches from each image at different locations with 1/4 size of the original image. The first four patches contain four quarters of the image without overlapping while the other five patches are randomly cropped from the input image. After that, we mirror the patches so that we double the training set.
- Training details
- Ground truth generation
- CSRNet architecture
- Experiment
- CSR的思路和Deeplab ASPP,RFB类似,都是通过不同的dilation rate进行不同感受野融合来加强结果的做法,整体来说比较work简单易理解。从这篇开始,dilation成为了crowd counting的标配


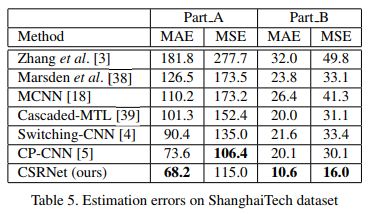
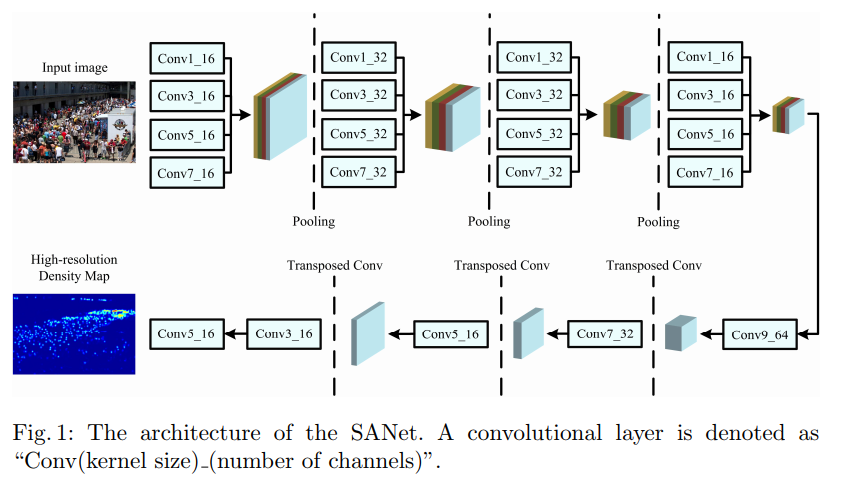
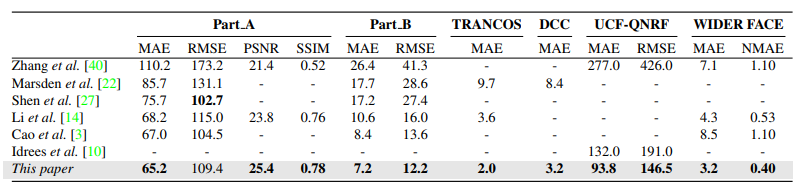
SANET
- paper Scale Aggregation Network for Accurate and Efficient Crowd Counting
- This section presents the details of the Scale Aggregation Network (SANet). We first introduce our network architecture and then give descriptions of the proposed loss function.
- Architecture
- Feature Map Encoder (FME) DECODE
- ensity Map Estimator (DME) ENCODE
- Normalization Layers —> Instance Normalization
- Feature Map Encoder (FME) DECODE
- Loss Function
- Euclidean Loss – Euclidean between pred and gt per pixel
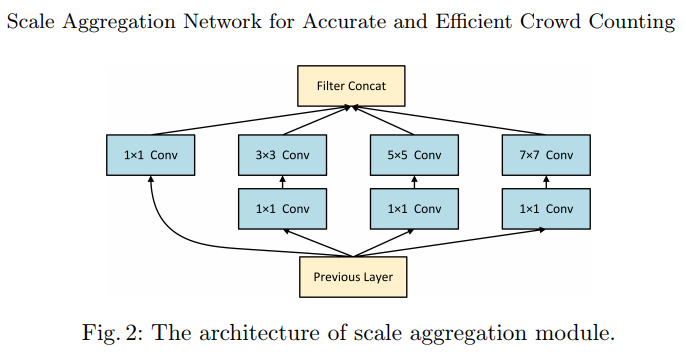
- Local Pattern Consistency Loss
- Beyond the pixel-wise loss function, we also incorporate the local correlation in density maps to improve the quality of results.We utilize SSIM index to measure the local pattern consistency of estimated density maps and ground truths. SSIM index is usually used in image quality assessment.
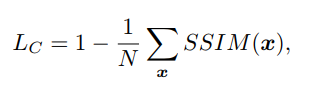
- Architecture
- Experiment
- 这其实就是使用inception block进行encode,普通deconv,外加使用in取代bn,在seg任务中IN的使用频率往往是更高也是更有效的。
- 提出了SSIM loss,提出了patch base的训练测试方法 –-–-– 个人感觉和SNIPER一样把图拆小处理是充满争议的做法
- 总体来说,在当时抛弃了VGG使用全新结构,改进了MCNN,简单高效,也是很有影响力的文章
SFCN
- paper Learning from Synthetic Data for Crowd Counting in the Wild
- home https://gjy3035.github.io/GCC-CL/
- In summary, this paper’s contributions are three-fold:
- We are the first to develop a data collector and labeler for crowd counting, which can automatically collect and annotate images without any labor costs. By using them, we create the first large-scale, synthetic and diverse crowd counting dataset. (使用GTA5开发了一套Crowd Counting Dataset合成器)
- Data Collection
- Scene Selection
- Person Model
- Scenes Synthesis for Congested Crowd
- Summary
- Properties of GCC
- GCC dataset consists of 15,212 images, with resolution of 1080 × 1920, containing 7,625,843 persons.

- Data Collection
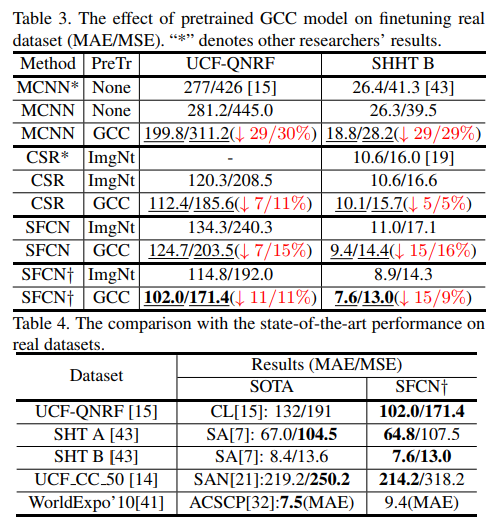
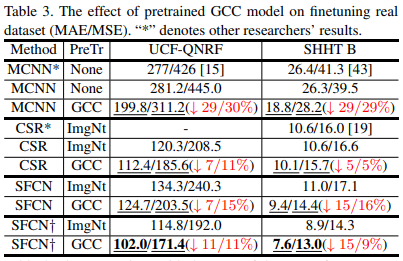
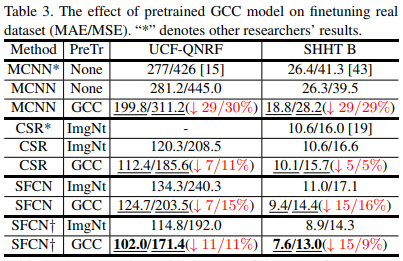
- We present a pretrained scheme to facilitate the original method’s performance on the real data, which can more effectively reduce the estimation errors compared with random initialization and ImageNet model. Further, through the strategy, our proposed SFCN achieves the state-of-the-art results. (使用GCC训练的预训练模型比直接使用imagenet的预训练模型diao多了,而且我们还开发了SFCN使效果更进一步)
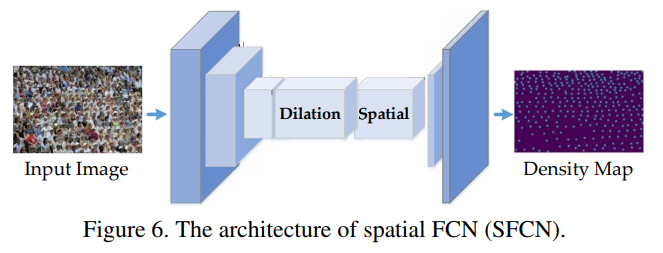
- Network Architecture
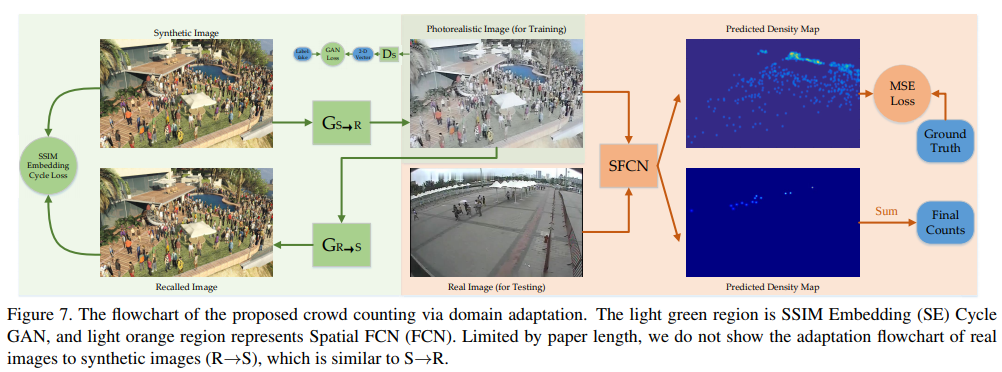
- In this paper, we design a spatial FCN (SFCN) to produce the density map, which adopt VGG-16 [34] or ResnNet-101 [12] as the backbone. To be specific, the spatial encoder is added to the top of the backbone. The feature map flow is illustrated as in Fig. 6. After the spatial encoder, a regression layer is added, which directly outputs the density map with input’s 1/8 size. Here, we do not review the spatial encoder because of the limited space. During the training phase, the objective is minimizing standard Mean Squared Error at the pixel-wise level; the learning rate is set as 10−5 ; and Adam algorithm is used to optimize SFCN.
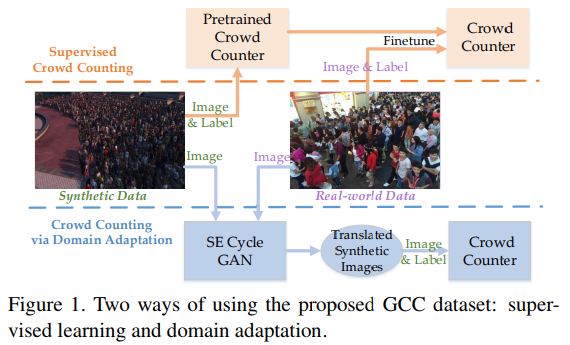
- We are the first to propose a crowd counting method via domain adaptation, which does not use any label of the real data. By our designed SE Cycle GAN, the domain gap between the synthetic and real data can be significantly reduced. Finally, the proposed method outperforms the two baselines.(propose了一种SE-CycleGAN,即使只在GCC数据集上训练也可以通过GAN使结果大幅提高,减少了real data和synthetic data的domain gap)
- We are the first to develop a data collector and labeler for crowd counting, which can automatically collect and annotate images without any labor costs. By using them, we create the first large-scale, synthetic and diverse crowd counting dataset. (使用GTA5开发了一套Crowd Counting Dataset合成器)
- Experiment
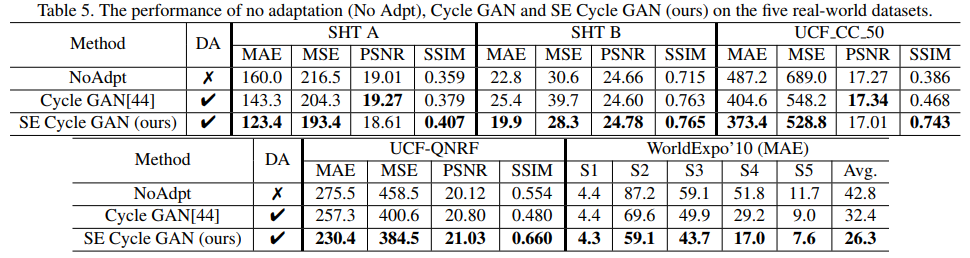
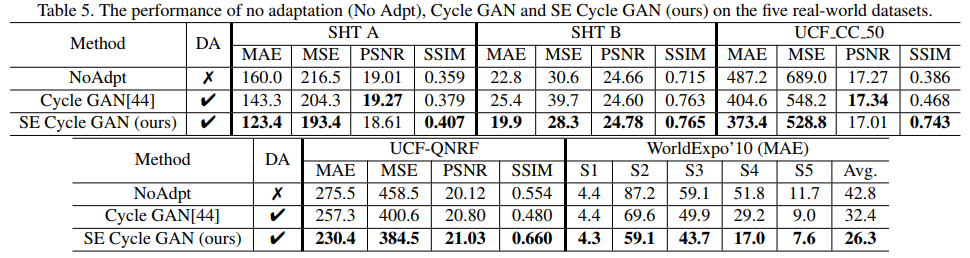
- 这是一篇非常全面的文章,兼顾数据集,模型,domain问题
- GCC-pretrained model非常work,值得推荐
- SFCN也非常简单好用,去除了patch的操作依然有不错的acc
CFF
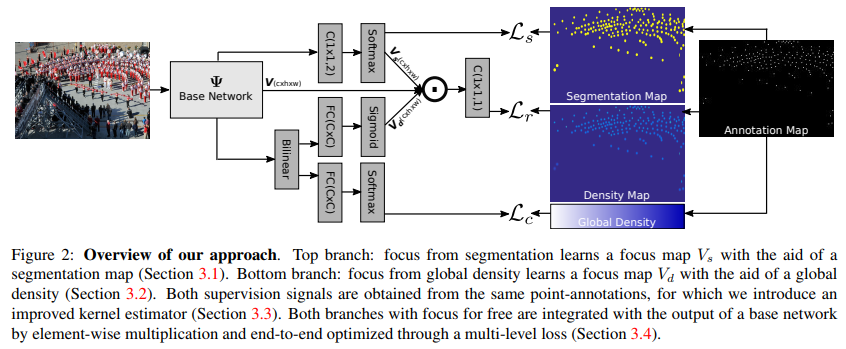
- Focus from segmentation
- Segmentation map
- annotation as a mask like seg
- Segmentation focus
- use focal loss
- Network detail
- After the output of the base network, we perform a 1 × 1 convolution layer with parameters θs ∈ R C×2×1×1 , followed by a softmax function δ to generate a per-pixel probability map Pi = δ(θsV ) ∈ R 2×W×H. From this probability map, the second value along the first dimension represents the probability of each pixel being part of the segmentation foreground. We furthermore tile this slice C times to construct a separate output tensor Vs ∈ R C×W×H, which will be used in the density estimation branch itself
- Segmentation map
- Focus from global density
- Global density
- compute Global density in each patch
- Global density focus
- focal loss
- Network details
- For network output V , we first perform an outer product B = V V T ∈ R C×C , followed by a mean pooling along the second dimension to aggregate the bilinear features over the image, i.e. Bˆ = 1 C PC i=1 B[:, i] ∈ R C×1 . The bilinear vector Bˆ is `2-normalized, followed by signed square root normalization, which has shown to be effective in bilinear pooling [18]. Then we use a fully connected layer with parameters θc ∈ R C×M followed by a softmax function δc to make individual prediction C = δc(θcBˆ) ∈ RM×1 for the global density. Furthermore, another fully-connected layer with parameters θd ∈ R C×C followed by sigmoid function δd also on top of the bilinear pooling layer is added to generate global density focus output D = δd(θdBˆ) ∈ R C×1 . We note that this results in a focus over the channel dimensions, complementary to the focus over the spatial dimensions from segmentation. Akin to the focus from segmentation, we tile the output vector into Vd ∈ R C×W×H, also to be used in the density estimation branch.
- focal loss
- Global density
- Non-uniform kernel estimation
- Experiment
- 为model 增加了seg分支用于attention,kernel分支,相较SA(67)提高了少量的结果
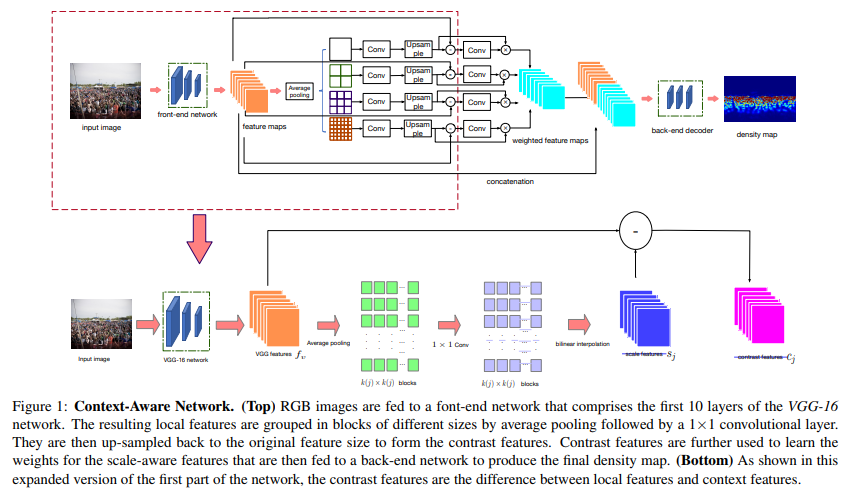
CAN
- paper Context-Aware Crowd Counting
- git https://github.com/weizheliu/Context-Aware-Crowd-Counting
Approach
Scale-Aware Contextual Features
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class ContextualModule(nn.Module):
def __init__(self, features, out_features=512, sizes=(1, 2, 3, 6)):
super(ContextualModule, self).__init__()
self.scales = []
self.scales = nn.ModuleList([self._make_scale(features, size) for size in sizes])
self.bottleneck = nn.Conv2d(features * 2, out_features, kernel_size=1)
self.relu = nn.ReLU()
self.weight_net = nn.Conv2d(features,features,kernel_size=1)
def __make_weight(self,feature,scale_feature):
weight_feature = feature - scale_feature
return F.sigmoid(self.weight_net(weight_feature))
def _make_scale(self, features, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, features, kernel_size=1, bias=False)
return nn.Sequential(prior, conv)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
multi_scales = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear') for stage in self.scales]
weights = [self.__make_weight(feats,scale_feature) for scale_feature in multi_scales]
overall_features = [(multi_scales[0]*weights[0]+multi_scales[1]*weights[1]+multi_scales[2]*weights[2]+multi_scales[3]*weights[3])/(weights[0]+weights[1]+weights[2]+weights[3])]+ [feats]
bottle = self.bottleneck(torch.cat(overall_features, 1))
return self.relu(bottle)- 通过不同程度的avgpool + attention mask + concate,完成全图的多scale attention
DSSINet
- paper Crowd Counting with Deep Structured Scale Integration Network
- git https://github.com/Legion56/Counting-ICCV-DSSINet

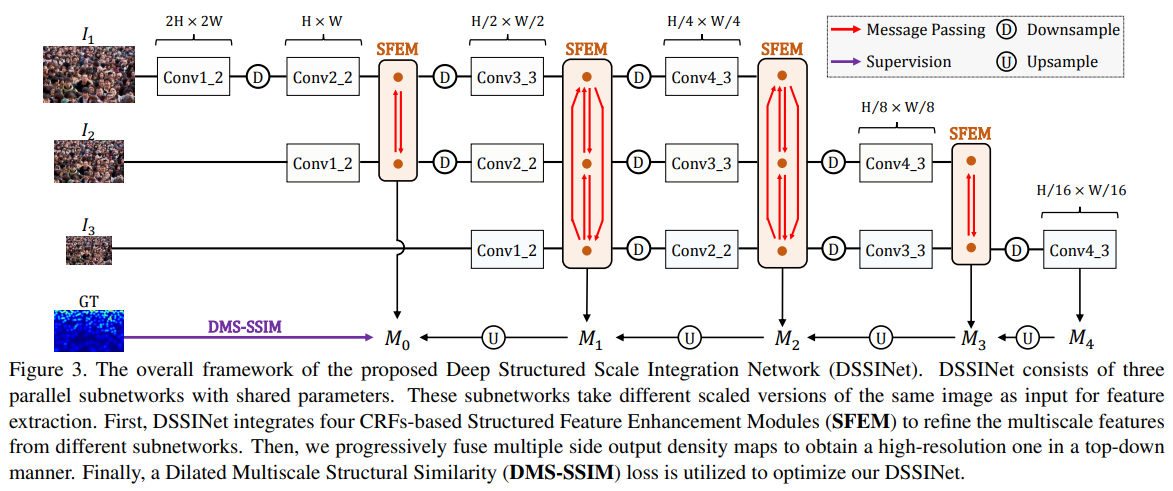
- base CRF构建了一个全新的模块;2.DMS-SSIM loss;3.在4个benchmark上均取得了sota
- 整体架构图,可以看出,SFEM这个MessagePassing模块是整个网络的核心
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40class MessagePassing(nn.Module):
def __init__(self, branch_n, input_ncs, bn=False):
super(MessagePassing, self).__init__()
self.branch_n = branch_n
self.iters = 2
for i in range(branch_n):
for j in range(branch_n):
if i == j:
continue
setattr(self, "w_0_{}_{}_0".format(j, i), \
nn.Sequential(
Conv2d_dilated(input_ncs[j], input_ncs[i], 1, dilation=1, same_padding=True, NL=None, bn=bn),
)
)
self.relu = nn.ReLU(inplace=False)
self.prelu = nn.PReLU()
def forward(self, input):
hidden_state = input
side_state = []
for _ in range(self.iters):
hidden_state_new = []
for i in range(self.branch_n):
unary = hidden_state[i]
binary = None
for j in range(self.branch_n):
if i == j:
continue
if binary is None:
binary = getattr(self, 'w_0_{}_{}_0'.format(j, i))(hidden_state[j])
else:
binary = binary + getattr(self, 'w_0_{}_{}_0'.format(j, i))(hidden_state[j])
binary = self.prelu(binary)
hidden_state_new += [self.relu(unary + binary)]
hidden_state = hidden_state_new
return hidden_state- 可以看到,对于 for hidden_state[i] in range(self.branch_n) 会和其他所有的非自己对象进行conv2d_dilated,输出和hidden_state[i]相同的channel数,然后prelu各自结合,再与原始值residual add
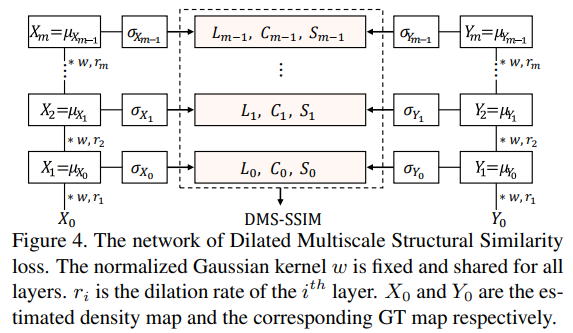
- loss部分,咋一看整个图,还以为作者是说吧所有层都算DMS-SSIM的意思,然而。。
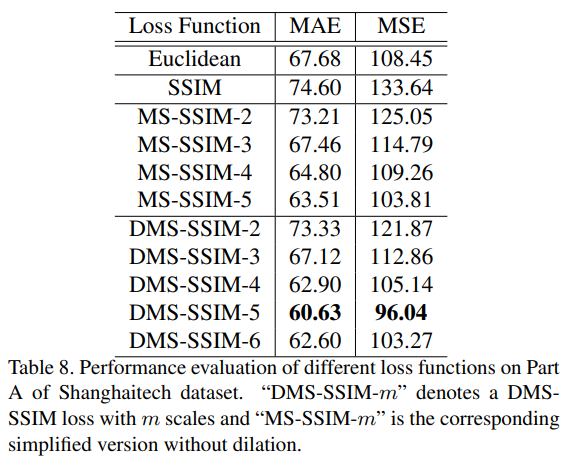
- 这里说的也比较清楚了,DMS-SSIM-m 代表有几个scale的DMS-SSIM loss,从代码实现上看,作者也仅仅用了最后一层算loss。structure示意图中4个SFEM也是对应了5个dilation scale,代码比较清楚
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100def t_ssim(img1, img2, img11, img22, img12, window, channel, dilation=1, size_average=True):
window_size = window.size()[2]
input_shape = list(img1.size())
padding, pad_input = compute_same_padding2d(input_shape, \
kernel_size=(window_size, window_size), \
strides=(1,1), \
dilation=(dilation, dilation))
if img11 is None:
img11 = img1 * img1
if img22 is None:
img22 = img2 * img2
if img12 is None:
img12 = img1 * img2
if pad_input[0] == 1 or pad_input[1] == 1:
img1 = F.pad(img1, [0, int(pad_input[0]), 0, int(pad_input[1])])
img2 = F.pad(img2, [0, int(pad_input[0]), 0, int(pad_input[1])])
img11 = F.pad(img11, [0, int(pad_input[0]), 0, int(pad_input[1])])
img22 = F.pad(img22, [0, int(pad_input[0]), 0, int(pad_input[1])])
img12 = F.pad(img12, [0, int(pad_input[0]), 0, int(pad_input[1])])
padd = (padding[0] // 2, padding[1] // 2)
mu1 = F.conv2d(img1, window , padding=padd, dilation=dilation, groups=channel)
mu2 = F.conv2d(img2, window , padding=padd, dilation=dilation, groups=channel)
mu1_sq = mu1.pow(2)
mu2_sq = mu2.pow(2)
mu1_mu2 = mu1*mu2
si11 = F.conv2d(img11, window, padding=padd, dilation=dilation, groups=channel)
si22 = F.conv2d(img22, window, padding=padd, dilation=dilation, groups=channel)
si12 = F.conv2d(img12, window, padding=padd, dilation=dilation, groups=channel)
sigma1_sq = si11 - mu1_sq
sigma2_sq = si22 - mu2_sq
sigma12 = si12 - mu1_mu2
C1 = (0.01*255)**2
C2 = (0.03*255)**2
ssim_map = ((2*mu1_mu2 + C1)*(2*sigma12 + C2))/((mu1_sq + mu2_sq + C1)*(sigma1_sq + sigma2_sq + C2))
v1 = 2.0 * sigma12 + C2
v2 = sigma1_sq + sigma2_sq + C2
cs = torch.mean(v1 / v2)
if size_average:
ret = ssim_map.mean()
else:
ret = ssim_map.mean(1).mean(1).mean(1)
return ret, cs
class NORMMSSSIM(torch.nn.Module):
def __init__(self, sigma=1.0, levels=5, size_average=True, channel=1):
super(NORMMSSSIM, self).__init__()
self.sigma = sigma
self.window_size = 5
self.levels = levels
self.size_average = size_average
self.channel = channel
self.register_buffer('window', create_window(self.window_size, self.channel, self.sigma))
self.register_buffer('weights', torch.Tensor([0.0448, 0.2856, 0.3001, 0.2363, 0.1333]))
def forward(self, img1, img2):
img1 = (img1 + 1e-12) / (img2.max() + 1e-12)
img2 = (img2 + 1e-12) / (img2.max() + 1e-12)
img1 = img1 * 255.0
img2 = img2 * 255.0
msssim_score = self.msssim(img1, img2)
return 1 - msssim_score
def msssim(self, img1, img2):
levels = self.levels
mssim = []
mcs = []
img1, img2, img11, img22, img12 = img1, img2, None, None, None
for i in range(levels):
l, cs = \
t_ssim(img1, img2, img11, img22, img12, \
Variable(getattr(self, "window"), requires_grad=False),\
self.channel, size_average=self.size_average, dilation=(1 + int(i ** 1.5)))
img1 = F.avg_pool2d(img1, (2, 2))
img2 = F.avg_pool2d(img2, (2, 2))
mssim.append(l)
mcs.append(cs)
mssim = torch.stack(mssim)
mcs = torch.stack(mcs)
weights = Variable(self.weights, requires_grad=False)
return torch.prod(mssim ** weights)- 这个levels就对应着文章中的m

- 与代码对应的计算方式在文中所示
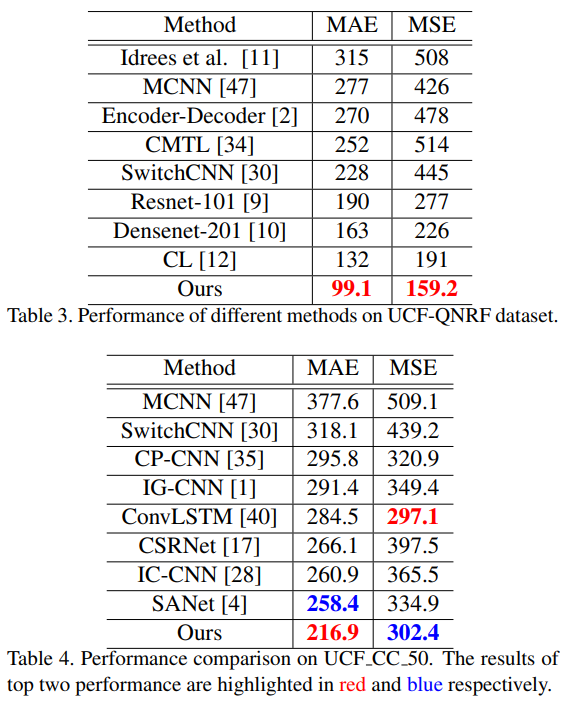
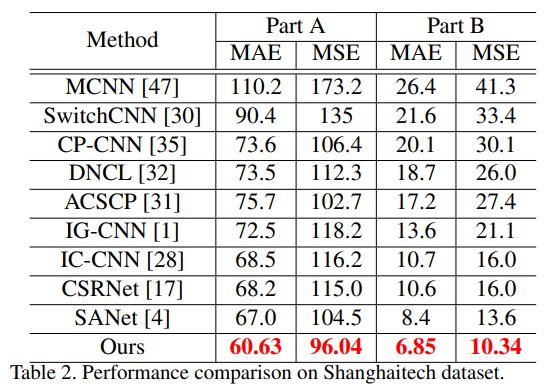
- Experiment
- exp的结果是really SOTA,几乎是最好的水平
- 神奇的方法,值得研究研究
Dataset
ShanghaiTechDataset (ShanghaiTech/SHT A & B)
- A Well Konwn BenchMark
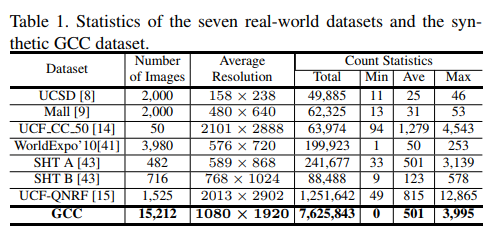
- Shanghaitech which contains 1198 annotated images, with a total of 330,165 people with centers of their heads annotated. As far as we know, this dataset is the largest one in terms of the number of annotated people. This dataset consists of two parts: there are 482 images in Part A which are randomly crawled from the Internet, and 716 images in Part B which are taken from the busy streets of metropolitan areas in Shanghai. The crowd density varies significantly between the two subsets, making accurate estimation of the crowd more challenging than most existing datasets. Both Part A and Part B are divided into training and testing: 300 images of Part A are used for training and the remaining 182 images for testing;, and 400 images of Part B are for training and 316 for testing
- paper https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Zhang_Single-Image_Crowd_Counting_CVPR_2016_paper.pdf
- git https://github.com/desenzhou/ShanghaiTechDataset
- Download url
GCC Dataset
- A Generated Dataset For Getting Pretrained Model
- home https://gjy3035.github.io/GCC-CL/
- Download url
- https://share-7a4a1d992bf4e98dee11852a48215193.fangcloud.cn/share/4625d2bfa9427708060b5a5981?folder_id=385000263093
- https://mailnwpueducn-my.sharepoint.com/personal/gjy3035_mail_nwpu_edu_cn/_layouts/15/onedrive.aspx?id=%2Fpersonal%2Fgjy3035%5Fmail%5Fnwpu%5Fedu%5Fcn%2FDocuments%2F%E8%AE%BA%E6%96%87%E5%BC%80%E6%BA%90%E6%95%B0%E6%8D%AE%2FGCC%20Dataset
- The data is collected from an electronic game Grand Theft Auto V (GTA5), thus it is named as “GTA5 Crowd Counting” (“GCC” for short) dataset. GCC dataset consists of 15,212 images, with resolution of 1080×1920, containing 7,625,843 persons. Compared with the existing datasets, GCC is a more large-scale crowd counting dataset in both the number of images and the number of persons.
Fudan-ShanghaiTech Dataset
- We collected 100 videos captured from 13 different scenes, and FDST dataset contains 150,000 frames, with a total of 394,081 annotated heads, in particular,the training set of FDST dataset consists of 60 videos, 9000 frames and the testing set contains the remaining 40 videos, 6000 frames.
- git https://github.com/sweetyy83/Lstn_fdst_dataset
- download url
Venice Dataset
- Venice. The four datasets discussed above have the advantage of being publicly available but do not contain precise calibration information. In practice, however, it can be readily obtained using either standard photogrammetry techniques or onboard sensors, for example when using a drone to acquire the images. To test this kind of scenario, we used a cellphone to film additional sequences of the Piazza San Marco in Venice, as seen from various viewpoints on the second floor of the basilica, as shown in the top two rows of Fig. 5. We then used the white lines on the ground to compute camera models. As shown in the bottom two rows of Fig. 5, this yields a more accurate calibration than in WorldExpo’10. The resulting dataset contains 4 different sequences and in total 167 annotated frames with fixed 1,280 × 720 resolution. 80 images from a single long sequence are taken as training data, and we use the images from the remaining 3 sequences for testing purposes. The ground-truth density maps were generated using fixed Gaussian kernels as in part B of the ShanghaiTech dataset.
- paper http://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_Context-Aware_Crowd_Counting_CVPR_2019_paper.pdf
- git https://github.com/weizheliu/Context-Aware-Crowd-Counting
- download url https://drive.google.com/file/d/15PUf7C3majy-BbWJSSHaXUlot0SUh3mJ/view
UCF-QNRF
- We introduce the largest dataset to-date (in terms of number of annotations) for training and evaluating crowd counting and localization methods. It contains 1535 images which are divided into train and test sets of 1201 and 334 images respectively.
- home https://www.crcv.ucf.edu/data/ucf-qnrf/
- paper https://www.crcv.ucf.edu/papers/eccv2018/2324.pdf
- download url
UCF-CC-50
- Only 50 images. This data set contains images of extremely dense crowds. The images are collected mainly from the FLICKR. They are shared only for the research purposes.
- home https://www.crcv.ucf.edu/data/ucf-cc-50/
- paper https://www.crcv.ucf.edu/papers/cvpr2013/Counting_V3o.pdf
- download url
WorldExpo’10 Dataset
- We introduce a new large-scale cross-scene crowd counting dataset. To the best of our knowledge, this is the largest dataset focusing on cross-scene counting. It includes 1132 annotated video sequences captured by 108 surveillance cameras, all from Shanghai 2010 WorldExpo2. Since most of the cameras have disjoint bird views, they cover a large variety of scenes. We labeled a total of 199,923 pedestrians at the centers of their heads in 3,980 frames. These frames are uniformly sampled from all the video sequences.
- home http://www.ee.cuhk.edu.hk/~xgwang/expo.html
- paper http://www.ee.cuhk.edu.hk/~xgwang/Project%20Page%20of%20Cross-scene%20Crowd%20Counting%20via%20Deep%20Convolutional%20Neural%20Networks_files/0994.pdf
- download url
- This paper is in cooperation with Shanghai Jiao Tong University. SJTU has the copyright of the dataset. So please email Prof. Xie (xierong@sjtu.edu.cn) with your name and affiliation to get the download link. It’s better to use your official email address. Thank you for your understanding.
- https://pan.baidu.com/s/1mgh7W4w#list/path=%2F password:765k
- Thank you for your attention to download our dataset. The dataset can be downloaded from Baidu disk or Dropbox:
- Baidu Disk: http://pan.baidu.com/s/1mgh7W4w password:765k
- Dropbox: https://www.dropbox.com/sh/kx9hctd9begjbn9/AAA65gQXG-xZ4e94wSNBDBrHa?dl=0
- This dataset is ONLY released for academic use. Please do not further distribute the dataset (including the download link), or put any of the videos and images on the public website. The copyrights belongs to Shanghai Jiao Tong University.
- Please kindly cite these two papers if you use our data in your research. Thanks and hope you will benefit from our dataset.Cong Zhang, Kai Zhang, Hongsheng Li, Xiaogang Wang, Rong Xie and Xiaokang Yang: Data-driven Crowd Understanding: a Baseline for a Large-scale Crowd Dataset. IEEE Transactions on Multimedia, Vol. 18, No.6, pp1048 - 1061, 2016.Cong Zhang, Hongsheng Li, Xiaogang Wang, and Xiaokang Yang. “Cross-scene Crowd Counting via Deep Convolutional Neural Networks”. in Proceedings of IEEE Conference on Computer Vision and Pattern Recognition 2015.If you have any detail questions about the dataset, please feel free to contact us (xierong@sjtu.edu.cnand xierong@sjtu.edu.cnandzhangcong0929@gmail.com zhangcong0929@gmail.com).Copyright (c) 2015, Shanghai Jiao Tong University All rights reserved. Best Regards, Rong
Mall Dataset
- The mall dataset was collected from a publicly accessible webcam for crowd counting and profiling research. Ground truth: Over 60,000 pedestrians were labelled in 2000 video frames. We annotated the data exhaustively by labelling the head position of every pedestrian in all frames. Video length: 2000 frames; Frame size: 640x480; Frame rate: < 2 Hz
- home http://personal.ie.cuhk.edu.hk/~ccloy/downloads_mall_dataset.html
- download url
UCSD Pedestrian Database
- The database contains video of pedestrians on UCSD walkways, taken from a stationary camera. All videos are 8-bit grayscale, with dimensions 238 × 158 at 10 fps. The database is split into scenes, taken from different viewpoints (currently, only one scene is available…more are coming). Each scene is in its own directory vidX where X is a letter (e.g. vidf), and is split into video clips of length 200 named vidfXY 33 ZZZ.y, where Y and ZZZ are numbers. Finally, each video clip is saved as a set of .png files.
- home http://www.svcl.ucsd.edu/projects/peoplecnt/
- pdf http://www.svcl.ucsd.edu/projects/peoplecnt/db/readme.pdf
- download url
SmartCity Dataset
- We have collected a new dataset SmartCity in the paper. It consists of 50 images in total collected from ten city scenes including office entrance, sidewalk, atrium, shopping mall etc.. Some examples are shown in Fig. 4 in our arxiv paper. Unlike the existing crowd counting datasets with images of hundreds/thousands of pedestrians and nearly all the images being taken outdoors, SmartCity has few pedestrians in images and consists of both outdoor and indoor scenes: the average number of pedestrians is only 7.4 with minimum being 1 and maximum being 14. We use this set to test the generalization ability of the proposed framework on very sparse crowd scenes.
- git https://github.com/miao0913/SaCNN-CrowdCounting-Tencent_Youtu
- paper https://arxiv.org/pdf/1711.04433.pdf
- download url
AHU-Crowd Dataset
- The crowd datasets are obtained a variety of sources, such as UCF and Data-driven crowd datasets to evaluate the proposed framework. The sequences are diverse, representing dense crowd in the public spaces in various scenarios such as pilgrimage, station, marathon, rallies and stadium. In addition, the sequences have different field of views, resolutions, and exhibit a multitude of motion behaviors that cover both the obvious and subtle instabilities.
- extreme crowd
- home http://cs-chan.com/downloads_crowd_dataset.html
- download url
CityStreet: Multi-View Crowd Counting Dataset
- The multi-view crowd counting datasets, used in our “wide-area crowd counting” paper, include our proposed dataset CityStreet, as well as two existing datasets PETS2009 and DukeMTMC repurposed for multi-view crowd counting.
- City Street: We collected a multi-view video dataset of a busy city street using 5 synchronized cameras. The videos are about 1 hour long with 2.7k (2704×1520) resolution at 30 fps. We select Cameras 1, 3 and 4 for the experiment (see Fig. 6 bottom). The cameras’ intrinsic and extrinsic parameters are estimated using the calibration algorithm from [52]. 500 multi-view images are uniformly sampled from the videos, and the first 300 are used for training and remaining 200 for testing. The ground-truth 2D and 3D annotations are obtained as follows. The head positions of the first camera-view are annotated manually, and then projected to other views and adjusted manually. Next, for the second camera view, new people (not seen in the first view), are also annotated and then projected to the other views. This process is repeated until all people in the scene are annotated and associated across all camera views. Our dataset has larger crowd numbers (70-150), compared with PETS (20-40) and DukeMTMC (10-30). Our new dataset also contains more crowd scale variations and occlusions due to vehicles and fixed structures.
- home http://visal.cs.cityu.edu.hk/research/citystreet/
- paper http://visal.cs.cityu.edu.hk/static/pubs/conf/cvpr19-wacc.pdf
- download url
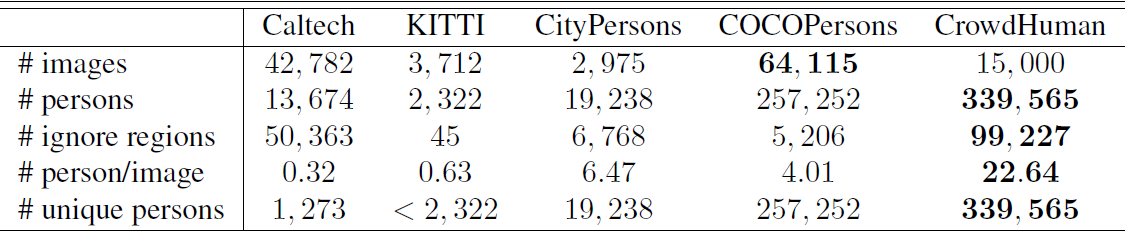
CrowdHuman
- MEGVII
- CrowdHuman is a benchmark dataset to better evaluate detectors in crowd scenarios. The CrowdHuman dataset is large, rich-annotated and contains high diversity. CrowdHuman contains 15000, 4370 and 5000 images for training, validation, and testing, respectively. There are a total of 470K human instances from train and validation subsets and 23 persons per image, with various kinds of occlusions in the dataset. Each human instance is annotated with a head bounding-box, human visible-region bounding-box and human full-body bounding-box. We hope our dataset will serve as a solid baseline and help promote future research in human detection tasks.
- home http://www.crowdhuman.org/
- paper https://arxiv.org/pdf/1805.00123.pdf
- download http://www.crowdhuman.org/download.html